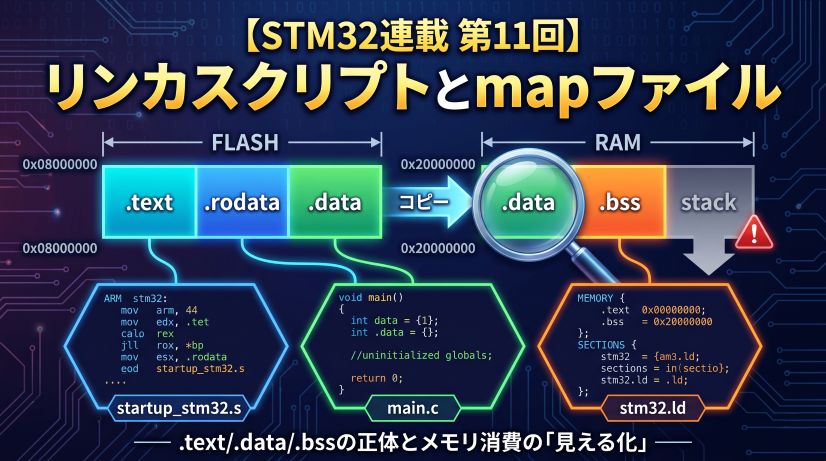
前回の第11回でリンカスクリプトとmapファイルを学びました。これで「空間(メモリ)」の話はひととおり終わりです。
最終回のテーマは 「最適化とアセンブラ」 です。
Cのコードがどのような機械語に変換されるか。コンパイラの最適化は何を変えて、何を変えてはいけないのか。volatile はなぜ必要なのか——第9回で触れた疑問に、今度はアセンブラレベルで決着をつけます。
📍 連載トップページ
✅ この記事でできるようになること
-O0/-O2/-Osの違いと使い分けを説明できるarm-none-eabi-objdumpでアセンブラ出力を見て、最適化の効果を確認できる- Thumb命令セットの基本的な読み方がわかる
volatileが最適化と衝突するメカニズムをアセンブラレベルで説明できる- 12回分の学びを「つよつよの条件」として自分の言葉で語れる
目次
- 最適化とは何か
- -O0 / -O2 / -Os の違い
- objdump でアセンブラを読む
- -O2 で起きること:代表的な最適化4選
- volatile 再確認
- 最適化の罠と回避策
- つよつよの条件まとめ
- まとめ
🔧 最適化とは何か
コンパイラの仕事
コンパイラは「Cのソースコードを機械語に変換する」ツールです。ただし、その変換方法はひとつではありません。
int add(int a, int b) {
return a + b;
}
このコードを「意味を保ちながら」機械語にする方法は無数にあります。コンパイラの最適化とは、「プログラムの観測可能な動作を変えずに、より速く・より小さくする変換」 のことです。
C言語の規格では、最適化が変えてよいのは「観測できないこと」だけと定められています。具体的には:
- 変えてよい:レジスタ割り当て、命令の並び替え、不要な変数の削除、ループの展開
- 変えてはいけない:
volatile変数の読み書きの回数と順序、volatileでない変数の最終的な値
これを理解すると「なぜ volatile が必要か」が自然に見えてきます。
同じCコードでも、コンパイラに渡すオプションによってまったく異なるアセンブラが生成されます。
⚙️ -O0 / -O2 / -Os の違い
GCC(arm-none-eabi-gcc)の最適化オプションと、その特徴です。第6回では「-O0では動くが-O2では壊れる」パターンをポインタ事故・UBと絡めて体験しました。今回はその仕組みをアセンブラレベルで解説します。
| オプション | 最適化レベル | 特徴 | 主な用途 |
|---|---|---|---|
-O0 |
なし | CコードとアセンブラがほぼV1対1対応。デバッグしやすい | 開発中・デバッグ時 |
-O1 |
軽度 | 基本的な最適化のみ。-O0とO2の中間 | あまり使わない |
-O2 |
標準 | 多くの最適化を適用。ほとんどの本番コードに適切 | 本番ビルド |
-O3 |
積極的 | さらに積極的(ループアンローリング強化など)。コードサイズが増える | 計算負荷が高い処理 |
-Os |
サイズ優先 | Flash節約を優先。コードが小さくなりキャッシュラインに収まりやすくなるため、結果的に -O2 より速くなるケースもある | Flash容量が厳しい場合 |
-Og |
デバッグ対応最適化 | デバッガ互換性を保ちながら軽度に最適化。-O0 より追いやすいケースも |
デバッグビルドで速度も欲しい場合 |
-O0 はCとアセンブラが1対1に近い反面、無駄なスタック操作やレジスタ退避が多く、かえってデバッガのステップ実行が追いにくい場面があります。最近の GCC では -Og(デバッグ最適化)が「デバッグしやすさと速度のバランス」として推奨されるケースが増えています。CubeIDE のデバッグビルドでも試してみる価値があります。
CubeIDEのデフォルトは、DebugビルドがO0、ReleaseビルドがOs(または-O2)です。
開発中は -O0 のままで問題ありませんが、本番前に -O2 や -Os でビルドして動作確認するのを忘れずに。最適化を有効にすると volatile 忘れが顕在化します。
🔍 objdump でアセンブラを読む
objdump とは
objdump は、コンパイル済みのバイナリファイル(ELF形式など)をアセンブラ表示に逆変換(逆アセンブル)するコマンドラインツールです。GNUバイナリユーティリティ(binutils)の一部として提供されており、コンパイラがCコードをどのような機械語に変換したかを確認するために使います。
Cソースコード ─[コンパイラ]→ 機械語(バイナリ)
機械語(バイナリ) ─[objdump]→ アセンブラ表示(人間が読める)
[MyProject.elf] ──(arm-none-eabi-objdump -d -S)──→ [output.asm]
デバッガで「変数がどのレジスタに入っているか」「最適化で命令が消えていないか」を確認したいとき、objdump は強力な手がかりになります。
objdump はターゲットアーキテクチャに対応した版が存在し、STM32に限らず幅広い環境で使えます。
| 環境 | 使うコマンド | 命令セット |
|---|---|---|
| STM32(Cortex-M) | arm-none-eabi-objdump |
Thumb-2 |
| Arduino UNO / Mega(AVR) | avr-objdump |
AVR |
| ESP32(Xtensa) | xtensa-esp32-elf-objdump |
Xtensa LX6 |
| Raspberry Pi / Linux ARM | aarch64-linux-gnu-objdump または objdump(ネイティブ) |
AArch64 |
| x86 PC(Linux) | objdump(標準インストール済み) |
x86-64 |
コマンド名が違うだけで、使い方(オプション)はどの環境もほぼ同じです。Arduino IDE の場合は、ビルド時に生成される .elf ファイルを avr-objdump -d に渡すと同様に確認できます。
実行場所:CubeIDE ではなく cmd(コマンドプロンプト)
objdump は CubeIDE のメニューから呼ぶものではなく、Windowsのコマンドプロンプト(cmd)やPowerShellから実行するコマンドラインツールです。
CubeIDE をインストールすると、内部に arm-none-eabi-objdump が同梱されています。これを cmd から直接呼び出します。
ステップ1:arm-none-eabi-objdump の場所を確認する
PowerShell を開き、以下のコマンドで自動検索します。
Get-ChildItem "C:\ST" -Recurse -Filter "arm-none-eabi-objdump.exe" -ErrorAction SilentlyContinue | Select-Object -ExpandProperty FullName
実行結果の例:
C:\ST\STM32CubeIDE_1.15.1\STM32CubeIDE\plugins\com.st.stm32cube.ide.mcu.externaltools.gnu-tools-for-stm32.12.3.rel1.win32_1.0.100.202403111256\tools\bin\arm-none-eabi-objdump.exe
バージョンによってフォルダ名の数字部分が変わりますが、構造は同じです。
ステップ2:PowerShell の PATH に追加する
見つかったパスの tools\bin フォルダを現在のセッションの PATH に追加します。
# 自動でパスを取得して PATH に追加(コピペで使える)
$env:PATH += ";$(Split-Path (Get-ChildItem 'C:\ST' -Recurse -Filter 'arm-none-eabi-objdump.exe' -ErrorAction SilentlyContinue | Select-Object -ExpandProperty FullName -First 1))"
動作確認:
arm-none-eabi-objdump --version
[System.Environment]::SetEnvironmentVariable(
"PATH",
$env:PATH + ";C:\ST\STM32CubeIDE_1.15.1\STM32CubeIDE\plugins\com.st.stm32cube.ide.mcu.externaltools.gnu-tools-for-stm32.12.3.rel1.win32_1.0.100.202403111256\tools\bin",
"User"
)
実行後、PowerShell を一度閉じて再度開くと次回から使えます。バージョン番号部分は Get-ChildItem で調べた実際のパスに合わせてください。
ステップ3:ELF ファイルのある Debug フォルダに移動して実行する
CubeIDE でビルドすると、プロジェクトフォルダ内に .elf ファイルが生成されます。
プロジェクト名\
Debug\ ← Debugビルドの出力先
プロジェクト名.elf ← これを使う
Release\
プロジェクト名.elf
PowerShell で Debug フォルダに移動して実行します。
cd D:\path\to\プロジェクト名\Debug
arm-none-eabi-objdump -d -S プロジェクト名.elf > output.asm
VSCode で開く場合:
code output.asm
Warning が出た場合
実行すると次のような警告が出ることがあります。
Warning: source file main.c is more recent than object file
これはエラーではなく、output.asm は正常に生成されています。
意味は「ソースファイルがビルド後に編集されたため、表示されるCソース行番号がアセンブラと若干ずれる可能性がある」というものです。Warningを消してきれいに見たい場合は、CubeIDE で一度リビルド(Ctrl+B)してから再度 objdump を実行してください。
主なオプション一覧
| オプション | 意味 | 使い場面 |
|---|---|---|
-d |
実行可能セクションを逆アセンブル | 基本。これだけで全関数が出る |
-S |
Cソースとアセンブラを混在表示 | -O0 ビルド時に特に有効 |
-h |
セクション一覧(.text/.data/.bssのサイズ)を表示 | arm-none-eabi-size の代替 |
--no-show-raw-insn |
機械語バイト列を非表示にして読みやすく | アセンブラだけ見たい場合 |
よく使うコマンドパターン
:: ① 全体を逆アセンブルしてファイルに保存
arm-none-eabi-objdump -d プロジェクト名.elf > output.asm
:: ② Cソースと混在表示(-O0 ビルド推奨)
arm-none-eabi-objdump -d -S プロジェクト名.elf > output_with_src.asm
:: ③ セクションサイズを確認(Flash/RAM使用量の概算)
arm-none-eabi-objdump -h プロジェクト名.elf
:: ④ 特定の関数だけ抽出(Windows の場合 findstr を使う)
arm-none-eabi-objdump -d プロジェクト名.elf | findstr /C:"<compute>" /C:"add" /C:"mov" /C:"bx"
-S(Cソース混在表示)を使うには、CubeIDEのビルド設定で「デバッグ情報を生成」がオンになっている必要があります(Debugビルドはデフォルトでオン)。Releaseビルドでは -g オプションが外れていることが多く、-S を付けてもCソースが表示されない場合があります。
実際の出力例
-d -S で生成される出力のイメージ(-O0 ビルド):
08000234 <compute>:
compute():
/workspace/Core/Src/main.c:45
int result = a + b;
8000234: push {r7}
8000236: sub sp, #12
8000238: add r7, sp, #0
/workspace/Core/Src/main.c:46
return result;
800023a: ldr r3, [r7, #4] ; a をロード
800023c: ldr r2, [r7, #8] ; b をロード
800023e: add r3, r3, r2 ; a + b
8000240: mov r0, r3 ; 戻り値にセット
8000242: add sp, #12
8000244: pop {r7}
8000246: bx lr ; return
左端の 8000234 はFlash上のアドレス(第1回で学んだ「アドレスだけが現実」がここに出る)。-O2 にすると、このコードがどこまで圧縮されるかを比較できます。
output.asm を読むときの目の付け所:
| 着目点 | 見るべき命令 | 意味 |
|---|---|---|
| 関数の入り口 | push {r4, lr} |
スタックに退避している——呼ばれた関数ほど多い |
| 変数の操作 | ldr / str |
RAMに読み書き。最適化で消えれば volatile を疑う |
| 関数の出口 | bx lr or pop {pc} |
リターン。-O2 では pop {pc} に変換されることも |
| 最適化で消えた処理 | 期待した命令がない | dead code elimination or 定数畳み込みが起きた証拠 |
Thumb命令・Thumb-2命令セットとは
objdumpの出力を読む前に、STM32が使う命令セットの背景を整理します。
📌 命令セット(ISA)とは
CPUが実行できる「命令の種類と形式の一覧」のこと。
アーキテクチャが違えば命令セットも違い、機械語のバイナリに互換性はない。
🔁 ARM → Thumb → Thumb-2 の流れ
⚖️ 3つの命令セットの比較
| ARM | Thumb | Thumb-2 | |
|---|---|---|---|
| 命令幅 | 32ビット固定 | 16ビット固定 | 16/32ビット混在 |
| コードサイズ | 大きい | 小さい(▲30%) | 小さい(▲25%) |
| 表現力 | 高い | 制限あり | 高い |
| 主な採用CPU | Cortex-A | 旧世代 | Cortex-M3/M4/M7 |
| STM32F401 | ❌ 使えない | ❌ 使えない | ✅ これだけ |
コンパイラが命令ごとに 16ビット版と32ビット版を自動で選択します。
- 単純な演算 → 16ビット命令(Flash節約)
- 大きな即値・複雑な操作 → 32ビット命令(表現力確保)
プログラマは意識しなくていい。コンパイラが最適な幅を選ぶ。
なぜ32ビット命令が必要なのか: 16ビットの命令フォーマットに収まらないケースがあるためです。たとえば movw/movt で32ビット即値を扱う場合、32ビット命令が必要になります。if (x != 0) のような条件付き実行も同様です。また、分岐先が遠い場合(16ビット命令では届かない距離へのジャンプ)も32ビット命令が必要で、大きなプログラムでは特に重要になります。「小ささ」と「表現力」を両立するために、混在方式が採用されました。
コンパイラが命令ごとにどちらの幅を選ぶかは、次のような判断で行われます。
Flashメモリ上での実際の配置イメージ:16ビット(2バイト)と32ビット(4バイト)の命令が、テトリスのように隙間なく詰まっています。
Flash内のアドレス
┌────────────┬────────────┬────────────────────────┬────────────┐
│ 0x08000000 │ 0x08000002 │ 0x08000004 │ 0x08000008 │
├────────────┼────────────┼────────────────────────┼────────────┤
│ add (16) │ sub (16) │ movw / bl (32bit) │ bx (16) │
│ 2バイト │ 2バイト │ 4バイト │ 2バイト │
└────────────┴────────────┴────────────────────────┴────────────┘
Cortex-Aシリーズは ARM命令モードと Thumbモードを切り替えられますが、Cortex-M(STM32)はThumb-2専用でARMモード自体が存在しません。
→ objdumpに表示される命令はすべてThumb-2です。
補足:Thumbモードとアドレスの奇数ビット(Tビット)
ARMアーキテクチャでは、関数ポインタのアドレスが奇数(最下位ビット=1)になっているとき、その関数はThumbモードで実行されることを示します。この最下位ビットは Tビット(Thumb bit) と呼ばれ、CPUが「次の命令をThumbモードで解釈するか、ARMモードで解釈するか」を判定するためのフラグです。第1回で学んだ「アドレスだけが現実」の話がここにも出てきます。実際のFlash上の配置アドレスは偶数ですが、ベクターテーブルに登録するアドレスは+1した奇数として記録されます。CubeIDEとHALが自動で処理するため意識する必要はありませんが、objdumpでベクターテーブルを覗くと奇数アドレスが並んでいるのを確認できます。
Thumb命令の基本的な読み方
objdumpの出力でよく登場する命令です。グループで覚えると読みやすくなります。
メモリアクセス
| 命令 | 意味 |
|---|---|
ldr r0, [r1] |
r1のアドレスからr0にロード(RAM→レジスタ) |
str r0, [r1] |
r0の値をr1のアドレスにストア(レジスタ→RAM) |
ldrb r0, [r1] |
1バイトだけロード(ldrは4バイト) |
strb r0, [r1] |
1バイトだけストア |
演算
| 命令 | 意味 |
|---|---|
add r0, r1, r2 |
r0 = r1 + r2 |
sub r0, r1, #4 |
r0 = r1 − 4 |
mov r0, #42 |
r0 = 42(即値代入) |
mul r0, r1, r2 |
r0 = r1 × r2 |
分岐・関数呼び出し
| 命令 | 意味 |
|---|---|
bl func |
funcを呼ぶ(戻りアドレスをlrに保存) |
bx lr |
lrのアドレスへジャンプ(関数リターン) |
b label |
labelへ無条件ジャンプ |
beq label |
直前の比較が Equal なら label へ |
スタック操作
| 命令 | 意味 |
|---|---|
push {r4, lr} |
r4とlrをスタックに積む(関数の先頭でよく出る) |
pop {r4, pc} |
r4とpcを復元(pcへpopで同時にリターン) |
🔬 -O2 で起きること:代表的な最適化4選
実際のコード例で最適化の効果を見ます。
1. 定数畳み込み(Constant Folding)
int result = 2 * 1000 * 1000; /* 2,000,000 */
/* -O0: 乗算命令が2回 */
mov r0, #2
mov r1, #1000
mul r0, r0, r1 /* r0 = 2000 */
mul r0, r0, r1 /* r0 = 2000000 */
/* -O2: コンパイル時に計算済み → 即値1回 */
movw r0, #0x4240
movt r0, #0x1e /* r0 = 2000000(即値) */
即値(Immediate value) とは、命令の中にデータが直接埋め込まれた数値のことです。RAMに読みに行く必要がなく、命令フェッチと同時にCPUに届くためゼロコストです。コンパイル時に計算できるものは実行時にゼロコストになります。
2. 不要コード除去(Dead Code Elimination)
int compute(int x) {
int unused = x * 100; /* 使われない変数 */
return x + 1;
}
/* -O0: unusedの計算がある */
mul r1, r0, #100
str r1, [sp] /* スタックに保存 */
add r0, r0, #1
/* -O2: unusedは完全に消える */
add r0, r0, #1
bx lr
3. インライン展開(Inlining)
static inline int square(int x) { return x * x; }
int main_calc(int a) {
return square(a) + square(a + 1);
}
/* -O0: squareへのbl(関数呼び出し)が2回 */
bl square
bl square
/* -O2: square の本体がmain_calcに展開される(blなし) */
mul r1, r0, r0 /* a * a */
add r2, r0, #1
mul r2, r2, r2 /* (a+1) * (a+1) */
add r0, r1, r2
bx lr
レジスタ割り当て(Register Allocation) ― CPU内部にある極めて少数の『超高速な作業机(レジスタ)』に、どの変数を置いて使い回すかの段取り ― の観点でも有利です。関数をまたいだ場合は「呼び出し規約」に従ってレジスタを退避しなければなりませんが、インライン展開後はすべて同一関数内の計算になり、コンパイラがより自由にレジスタを割り当てられます。
ただし副作用もあります。同じ関数を多くの場所でインライン展開すると、コードサイズが肥大化します。コードが大きくなると命令キャッシュ(I-Cache)のヒット率が下がり、結果として -O0 より遅くなるケースもあります。コンパイラは「展開するかしないか」をコストモデルで自動判断しますが、最終的には計測で確認するのが鉄則です。
inline キーワードはコンパイラへの 勧告(ヒント) であり、展開するかどうかの最終決定権はコンパイラにあります。-O2 以上では inline がなくても展開されることがあり、逆に inline を付けても展開されないこともあります。
また static inline と inline は意味が違います。static がなければ関数に外部リンケージが生じ、別の翻訳ユニットから参照される可能性のために実体(コピー)が残ることがあります。ヘッダに書くインライン関数には static inline を付けるのが安全です。
4. ループアンローリング(Loop Unrolling)
uint32_t sum = 0;
for (int i = 0; i < 4; i++) {
sum += arr[i];
}
/* -O2: ループを展開して4回の命令に変える */
ldr r1, [r0]
ldr r2, [r0, #4]
add r1, r1, r2
ldr r2, [r0, #8]
add r1, r1, r2
ldr r2, [r0, #12]
add r0, r1, r2
ループカウンタの比較・分岐がなくなります。
これが有効な理由は パイプラインストール にあります。CPUは命令を先読みして並列実行しますが、条件分岐(beq/blt など)があると「次に実行する命令」の予測が外れることがあり、予測ミスの分だけ処理が止まります。これをパイプラインストールと呼びます。分岐を除去することでこのロスがなくなります。
トレードオフとして、展開した命令がその分Flashを消費します。イテレーション数が少なく固定の場合に有効で、大きなループに適用するとFlash不足になることもあります。
最適化4選まとめ:メリットとリスク
| 最適化手法 | メリット | リスク・注意点 |
|---|---|---|
| 定数畳み込み | 実行時の計算コストがゼロ | 特になし(安全) |
| 不要コード除去 | Flash・実行時間を節約 | デバッガで変数が「消えて」見えなくなる(-O0 で確認) |
| インライン展開 | 関数呼び出しオーバーヘッドがゼロ | コードサイズ肥大 → I-Cacheヒット率低下で逆に遅くなることも |
| ループアンローリング | パイプラインストールを排除 | Flash消費量が増える |
どの最適化も「速くなる可能性がある」だけで、実際に速くなったかは計測で確認するのが鉄則です。
⚡ volatile 再確認
なぜ volatile が必要か(アセンブラで見る)
第9回で「volatile がないと -O2 でハングする」と学びました。今回はその理由をアセンブラで確認します。
/* ISR共有フラグ(volatileなし) */
uint8_t g_flag = 0;
void wait_for_flag(void) {
while (g_flag == 0) {
/* 待つ */
}
}
/* -O0: 毎回 g_flag をRAMから読む */
.loop:
ldrb r0, [r1] /* RAMからg_flagをロード */
cmp r0, #0
beq .loop /* 0ならループ */
bx lr
/* -O2: g_flag を一度だけ読み、レジスタに保持してしまう */
ldrb r0, [r1] /* RAMからg_flagをロード(1回だけ!) */
cbz r0, .inf_loop /* 0なら無限ループへ */
bx lr
.inf_loop:
b .inf_loop /* RAMを再読しないまま永遠にループ */
コンパイラは「関数内でg_flagを変更するコードはない」と判断し、RAMの再読を省略します。ISRが書き換えても、CPUはレジスタのコピーしか見ていないので気づきません。
/* ✅ volatile を付ける */
volatile uint8_t g_flag = 0;
/* -O2(volatile付き): 毎回RAMから読む */
.loop:
ldrb r0, [r1] /* 毎回RAMから読む(最適化されない) */
cmp r0, #0
beq .loop
bx lr
volatile は「このメモリアクセスはCPU以外(ISR・DMA・ハードウェア)が変更する可能性がある」とコンパイラに伝えるキーワードです。
-O2(volatile なし)で何が起きているか:
RAMの変化に永遠に気づかない
volatile は「最適化禁止」ではなく、「このアドレスへのすべてのアクセスを省略・並び替え禁止」という意味です。
- アクセスの回数を保証する(省略しない)
- アクセスの順序を保証する(並び替えない)
レジスタ演算自体は最適化されます。あくまでRAMへの「読み書き」の回数と順序を保証するものです。
第10回でDMAバッファのキャッシュコヒーレンシ問題を学びました。あの問題と今回の volatile の問題は、「CPUが見ている値と、実際の値がズレる」 という意味で本質的に同じ構造を持っています。
- volatile忘れ → コンパイラがRAM再読を省略 → CPUはレジスタのコピーしか見ない
- キャッシュコヒーレンシ → DMAがRAMを更新してもCPUはキャッシュのコピーしか見ない
解決の方向も同じです。「CPUに、必ず現物(RAM)を見させる」こと。volatile はコンパイラへの命令、__DMB() はハードウェアへの命令、というだけの違いです。
volatile が防ぐのはコンパイラによる並び替えとキャッシュです。CPUがハードウェアレベルで命令を並び替える「アウトオブオーダー実行」は、volatile では防げません。それを防ぐには __DMB()(Data Memory Barrier)などのメモリバリア命令が必要です。
ただし STM32F401(Cortex-M4)はアウトオブオーダー実行を持ちません。命令は常にプログラム順に実行されます。そのため、Cortex-M4では volatile だけで実用上ほぼ足りますが、Cortex-A(Linux組み込みなど)に移植するときはこの区別が重要になります。
⚠️ 最適化の罠と回避策
罠1:ISR共有変数への volatile 忘れ
第9回アンチパターン2そのものです。-O0では動き、-O2で突然ハングする。
回避策: ISRと共有するすべての変数に volatile を付ける。
罠2:volatile でも非アトミックな更新
volatile uint32_t g_count; /* volatile があってもアトミックではない */
/* ISR */
void TIM2_IRQHandler(void) {
g_count++; /* LDR + ADD + STR の3命令 → mainと競合する可能性 */
}
第9回アンチパターン4で詳述した通り、volatile はアクセスの省略を防ぐだけで、複数命令の原子性は保証しません。4バイト境界にアラインされた 32ビット以下の整数1変数の単純な読み書きはアーキテクチャ上アトミックですが、インクリメント(RMW)は非アトミックです(__packed 構造体など非アライン配置の場合は別途確認が必要)。
回避策: 重要なカウンタ更新はクリティカルセクションで保護する、または __disable_irq() で囲む。
罠3:メモリバリアが必要な場面
DMAバッファへの書き込み順序をコンパイラが並び替える場合があります。
g_tx_buf[0] = 'H';
g_tx_buf[1] = 'i';
__DMB(); /* Data Memory Barrier:DMA起動前に書き込みを確実に完了させる */
HAL_UART_Transmit_DMA(&huart2, g_tx_buf, 2);
STM32F401(Cortex-M3/M4)ではアウトオブオーダー実行がないため実際には問題になりにくいですが、移植性のあるコードにはバリアを入れる習慣をつけておくと安全です。
罠4:関数単位で最適化を無効にする
ハードウェア初期化など、最適化してほしくない関数だけ -O0 にする方法があります。
/* この関数だけ最適化を無効にする */
__attribute__((optimize("O0")))
void hw_init_sensitive(void) {
/* デリケートな初期化シーケンス */
GPIOA->BSRR = GPIO_BSRR_BS5;
for (volatile int i = 0; i < 100; i++); /* 意図的なウェイト */
GPIOA->BSRR = GPIO_BSRR_BR5;
}
🏆 つよつよの条件まとめ
この連載で学んできたことを、「つよつよエンジニアの思考回路」として整理します。
12回分の積み上げ
| 回 | テーマ | 得た武器 |
|---|---|---|
| 第0回 | 組み込みの世界観 | 「空間・時間・電気」という3軸 |
| 第1回 | アドレスの世界 | アドレスこそが現実 |
| 第2回 | Flash/RAM/スタック | 変数の「住所」を意識する |
| 第3回 | 構造体とパディング | メモリの「形」を読む |
| 第4回 | レジスタ操作 | BSSRで直接叩く快感 |
| 第5回 | ポインタ=型付きアドレス | ポインタは怖くない、武器だ |
| 第6回 | ポインタ事故 | 壊れ方を知って強くなる |
| 第7回 | 時間の世界 | 計測なき最適化は迷信 |
| 第8回 | 割り込みの仕組み | NVICとベクターテーブルを読む |
| 第9回 | 割り込みアンチパターン | 「壊れパターン」を全部知っている |
| 第10回 | DMA | CPUの仕事を選ぶ |
| 第11回 | リンカスクリプト・map | メモリの全貌を「見える化」する |
| 第12回 | 最適化・アセンブラ | コンパイラの変換を自分で検証する |
つよつよエンジニアの5つの習慣
変数名ではなく「このデータはどのアドレスにいるか」を意識する。スタック上か、グローバル領域か、ペリフェラルのレジスタか。それだけで「DMAに渡せるか」「ISRから安全にアクセスできるか」がわかる。
「たぶん遅い」「たぶん速い」は禁止。DWT CYCCNTで実測してから話す。プロファイルなき最適化は、間違った場所を削って正しい場所をそのままにする。
objdump -d でアセンブラを眺める習慣をつける。「このコードはコンパイラにとってどう見えているか」を知ると、volatile・アトミック・最適化の問題が事前に見えてくる。
NULLデリファレンス、スタックオーバーフロー、volatile忘れ、DMAバッファの誤り——これらの「壊れるパターン」を頭に入れておくと、バグを見たときに「あの罠だ」と即座に判断できる。
ISRは通常の関数ではない。コンテキストスイッチが暗黙に起きる「割り込まれる世界」と「割り込む世界」の境界線を、常に意識してコードを書く。
つよつよの本質:「見えていないものを見る」
組み込みエンジニアの強さは、「普通のプログラマには見えないものが見える」 ことです。
- Arduinoユーザーには見えない → レジスタの値
- デバッガがなければ見えない → スタックの状態
- -O0でしか動かさなければ見えない → 最適化の影響
- mapファイルを見なければわからない → どのモジュールがRAMを食っているか
- objdumpを見なければわからない → コンパイラが何をしたか
この連載でその「見る目」を育ててきました。
「アドレスだけが現実」
変数名、関数名、型——これらはすべてプログラマの便宜のための抽象です。CPUにとっての現実は「アドレスとその中身のビット列」だけです。
この事実を腹落ちさせたとき、組み込みの「怖い」が「面白い」に変わります。
スタックもレジスタも、割り込みもDMAも、リンカスクリプトも最適化も——すべては「アドレスとビットを正しく扱う技術」です。
まとめ
今回学んだこと:
| 概念 | 内容 |
|---|---|
| 最適化の原則 | 「観測可能な動作を変えずに、速く・小さくする」 |
| -O0 vs -O2 | -O0は1対1対応でデバッグ向け、-O2は本番向け |
| 定数畳み込み | コンパイル時に計算できるものは実行時ゼロコスト |
| インライン展開 | 小さな関数の呼び出しコストをゼロにする |
| dead code elimination | 使われない変数・コードは完全に消える |
| volatile の意味 | RAMへのアクセス回数・順序を保証する(省略禁止) |
| objdump | アセンブラ出力でコンパイラの変換を検証できる |
第0回から第12回まで、「ポインタの先にある組み込みの世界」にお付き合いいただきありがとうございました。
この連載で伝えたかったことは3つです:
- アドレスを見る目 — メモリ・レジスタ・スタックの正体
- 時間を意識する習慣 — 計測・割り込み・DMAのリズム
- 壊れ方から学ぶ強さ — ポインタ事故・アンチパターン・最適化の罠
これからも 「動いたからよし」ではなく「なぜ動くか」を問い続ける組み込みエンジニアでいてください。
ポインタとは、物理的な配線と論理的な変数を結びつける唯一の架け橋です。 その橋を自分の目で確かめられる力を、この連載で少しでも手に入れてもらえたなら幸いです。
Cを書いているとき、頭の中に「アドレス」が浮かぶようになった——それが、この連載を読んだ証です。
あとがき:生成AIと組み込み開発
最後に、この連載を書きながらずっと考えていたことを残しておきます。
生成AIはとても便利なツールで、私自身も日常的に活用しています。コードの雛形を作る、エラーの原因を絞り込む、データシートの英文を素早く読む——こうした場面でのスピードアップは本物です。
ただ、生成されたものを脳死で使うだけでは、やればやるほど限界が来るとも感じています。特に組み込みの世界では。
なぜか。
生成AIはコードを「それらしく」出力します。でも「それらしいコード」が実際のハードウェアで動くかどうかは、デバッガを繋いで波形を見て、自分の手で確認するしかない場面が必ずあります。
- オシロスコープの波形が「なんかおかしい」
- デバッガで止めたら、変数の値が「論理的にありえない」数になっている
- -O2 にした途端に動かなくなった
特に組み込みの現場では、ソフトウェアが直接ハードウェアと接触します。センサーの応答タイミング、電源投入シーケンス、通信バスのノイズ——こういった「現物を前にしないと再現しない問題」に、組み込みエンジニアは日常的に遭遇します。AIに完璧なコードを書いてもらっても、実際の基板に載せた瞬間に動かない、という状況はいくらでも起きます。そしてその原因究明は、結局デバッガとオシロスコープを見ながら、自分の手で一歩ずつ追いかけるしかありません。
こういう瞬間にAIに聞いても、「それらしい回答」は返ってきます。でも自分にレジスタの知識がなければ、その回答が正しいかどうか判断できない。
生成AIを本当に武器にするには、出力を検証できる地力が要ります。そしてその地力は、一度でも「なぜ壊れるか」を自分で追いかけた経験から生まれます。
この連載が、その「検証できる力」を育てる一助になれば、これ以上嬉しいことはありません。
デバッガとオシロスコープの前に座って、自分の目で確かめる。その習慣だけは、どんなAIが登場しても変わらない組み込みエンジニアの核心だと思っています。
🚀 その先の景色:さらなる高みへ
この連載はここで一旦幕を閉じますが、皆さんが手に入れた「地力」があれば、さらに高く険しい山にも挑めるはずです。今後は「応用編」として、以下のようなテーマについても発信していきたいと考えています。
RTOS(Real Time OS)
今回の連載で学んだ「割り込み」や「スタック」の知識が、最も火を吹く領域です。FreeRTOSなどを題材に、複数のタスクがどうやって「同時に」動いているのか。セマフォやキューを使って、いかに安全にタスク間通信を行うか。ベアメタル(OSなし)を卒業し、複雑なシステムを「設計」する力を養います。
低消費電力(Low Power)設計
「動かす」のは簡単ですが、「賢く眠らせる」のは芸術の域です。Sleep、Stop、Standbyモードの使い分けや、復帰のタイミング、低消費電力時のペリフェラルの挙動など、バッテリー駆動デバイスには欠かせない技術を深掘りします。
ファームウェア更新とブートローダー
製品開発で必ず直面するのが「どうやって安全にプログラムを書き換えるか」です。Flashメモリのセクター管理から、自作ブートローダーによるアップデートの仕組みまで、現場で即戦力となる知識を扱います。
DSP(デジタル信号処理)と数学
Cortex-M4のFPU(浮動小数点演算ユニット)やDSP命令を使い倒します。センサーデータのフィルタリングやFFT(高速フーリエ変換)など、数学をコードに落とし込み、物理世界をリアルタイムに解析する手法を学びます。
モダンな開発プロセス(Unit Test / CI)
「実機がないとテストできない」からの脱却。ハードウェアを抽象化し、PC上でユニットテストを回す手法や、GitHub Actionsなどを用いたCI(継続的インテグレーション)を組み込みの世界に持ち込む方法を模索します。
組み込みエンジニアの旅に、終わりはありません。
でも、ポインタとアドレスという「一番低い、けれど一番大切な土台」を固めた皆さんなら、どんな新しい技術も自分の力で解釈できるはずです。
また次の「ポインタの先」でお会いしましょう!
よくある質問(FAQ)
Q. -O2 で動かないコードが -O0 では動く。どこを疑うべきですか?
まず volatile の付け忘れを疑ってください。ISRやDMAで共有している変数、ハードウェアレジスタへのポインタに volatile が付いているか確認します。次に、ローカル変数の寿命(スタック解放後のアクセス)を確認します。
Q. __attribute__((optimize("O0"))) はどんな場面で使いますか?
ハードウェアの初期化シーケンスで「命令の順序を厳密に守りたい」場合や、タイミングを手動で調整したいウェイトループに使います。ただし多用するとFlashサイズが増えます。
Q. Thumb命令とARM命令はどう使い分けられますか?
Cortex-M(M0〜M7)はThumb-2命令セット専用で、ARMモード(32ビット幅命令)には切り替えられません。Thumb-2は16ビット命令と32ビット命令の混在で、コードサイズとパフォーマンスのバランスが良いのが特徴です。objdump の出力に表示されるのはすべてThumb命令です。
Q. -Os と -O2 ではどちらを本番に使うべきですか?
Flashに余裕があれば -O2、Flash容量が厳しければ -Os を選びます。速度を優先したい処理(FFT、制御演算)は -O2 や -O3、コードサイズ全体を減らしたいプロジェクトは -Os が典型的な選択です。
Q. この連載の次に読むべきものは?
- リアルタイムOS:FreeRTOS入門(タスク・キュー・セマフォ)
- ペリフェラルの深掘り:STM32のSPI/I2C/ADCをDMAで使いこなす
- 安全設計:MISRA-C、機能安全、ウォッチドッグ
- ネットワーク:LwIP、MQTT、TLS on STM32