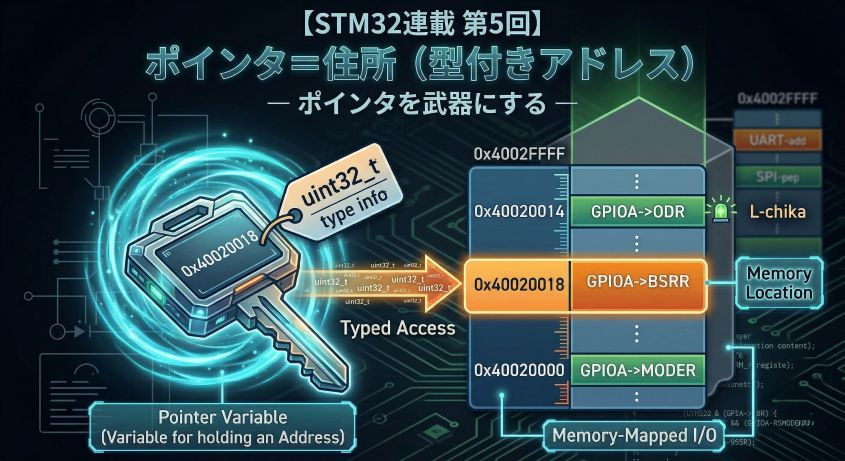
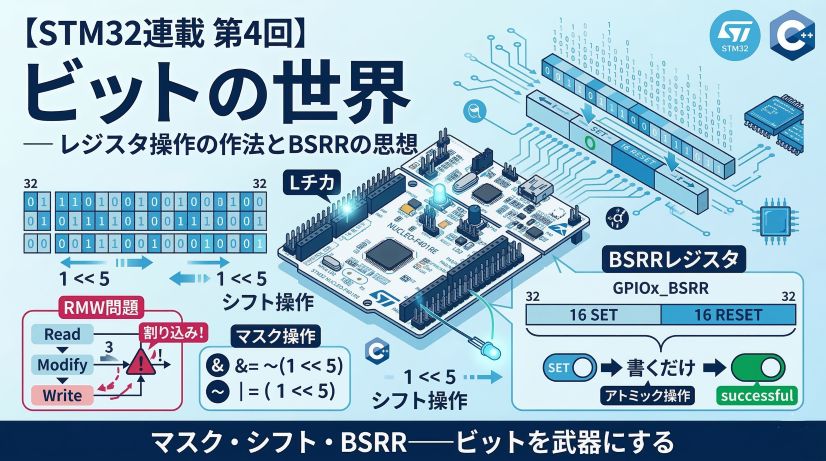
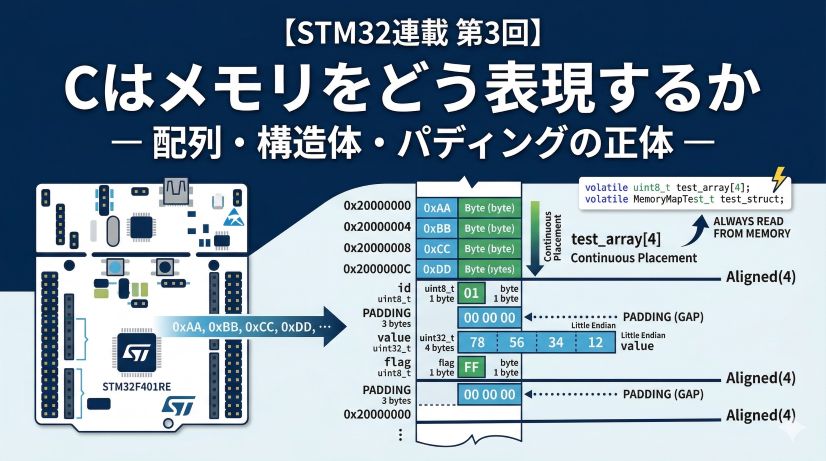
前回の第6回で、ポインタの「壊れ方」を6種類体験しました。ここまでの6回は 「空間の世界」――アドレス・メモリ・レジスタ、CPUがデータを どこに置くか の話でした。
今回から Phase 2:時間の世界 に入ります。
「このコードは何秒かかっているか?」
組み込みエンジニアが真っ先に答えられなければならない質問です。しかし多くの初学者は「なんとなく速い」「たぶん大丈夫」で済ませてしまいます。
計測なき最適化は迷信です。 今回は「1クロックサイクルの重さ」を実感し、µs単位で実行時間を測る武器を手に入れます。
この記事の核心は「DWT CYCCNT の使い方」と「計測する習慣」の2つです。 クロックツリーの詳細は読み飛ばしても構いません。
📍 連載トップページ
✅ この記事でできるようになること
- クロック周波数と「1サイクルの時間」を計算できる
- HAL_GetTick() と DWT CYCCNT の違いと使い分けを説明できる
- DWT CYCCNT を有効化してµs単位の実行時間を計測できる
- GPIOトグル+オシロスコープ(またはロジアナ)で実行時間を実測できる
- 「計測してから議論する」という組み込みエンジニアの思考習慣を身につける
目次
- なぜ「時間」が組み込みの本質なのか
- クロックとは何か
- 組み込みで使える「時間の道具」
- DWT CYCCNT ― サイクル単位の計測器
- 実測してみる(実験1〜3)
- GPIOトグル+オシロスコープで測る
- DWT CYCCNT の注意点
- 実用シナリオ
⏱️ なぜ「時間」が組み込みの本質なのか
PCのプログラムは「速ければ速いほどいい」ですが、組み込みは「ちょうどよい時間に、確実に動く」 ことが要求されます。
- モーター制御:1ms ごとに PWM デューティを更新しなければブレる
- 通信プロトコル(UART/SPI):1ビットのタイミングがずれたらデータ化け
- センサー読み取り:サンプリング周期が乱れると計測精度が落ちる
- 安全システム:規定時間内に応答しないとウォッチドッグがリセットをかける
「なんとなく速い」は通用しません。 実行時間を数値で把握することが、組み込みエンジニアの基礎体力です。
🕐 クロックとは何か
CPUが「時間を刻む」仕組み
マイコンの中には 水晶振動子 や PLL(Phase Locked Loop) が生成する一定周期の電気信号が流れています。これが クロック です。
CPUはこのクロックに同期して動作します。クロックは「High(高電圧)」と「Low(低電圧)」を繰り返す電気信号で、Low→High に切り替わる瞬間(立ち上がりエッジ) のたびに CPU が1動作進みます。
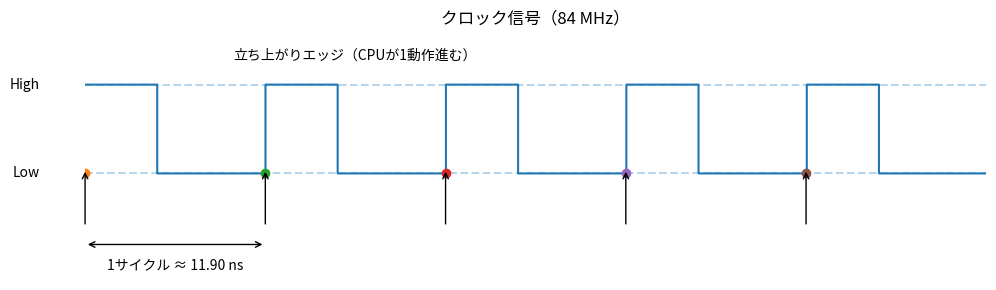
クロック信号のイメージ。立ち上がりエッジのたびに CPU が1動作進む。84MHz では1サイクル ≈ 12 ns
1サイクルは「High になってから、次に High になるまで」の時間です。84MHz なら、これが 1秒間に 8,400万回 繰り返されます。
NUCLEO-F401RE のクロック
STM32F401RE の最大クロック周波数は 84MHz です。
| クロック設定 | 周波数 | 1サイクルの時間 |
|---|---|---|
| 最大(デフォルト) | 84 MHz | 約 11.9 ns |
| 中速 | 42 MHz | 約 23.8 ns |
| 低速(省電力) | 16 MHz(内部RC) | 約 62.5 ns |
1Hz = 1秒間に1サイクル。1MHz = 1秒間に100万サイクル。84MHz = 1秒間に8,400万サイクル。
1サイクルの時間は周波数の逆数です:
T = \frac{1}{f} = \frac{1}{84 \times 10^6 \text{ Hz}} \approx 11.9 \text{ ns}ESP32(240MHz)なら約4.2ns、AVR(16MHz)なら約62.5nsと、同じ式で計算できます。
クロックツリー ― 84MHz はどこから来るのか
「84MHz」は魔法の数字ではありません。マイコン内部で クロックツリー と呼ばれる逓倍・分周の連鎖によって生成されます。
NUCLEO-F401RE で CubeMX のデフォルト設定を使うと HSI(内部RC発振器、16MHz)がソースになります:
内部RC発振器(HSI): 16 MHz
↓ PLLM=16 で分周 → 1 MHz
↓ PLLN=336 で逓倍 → 336 MHz
↓ PLLP=4 で分周
SYSCLK: 84 MHz ← CPU が使うクロック
↓
HCLK: 84 MHz ← AHBバス(RAM・DMA)
↓ ↓
APB1: 42 MHz APB2: 84 MHz
(TIM2-7など) (TIM1,8・SPI1・USART1など)
低周波の元クロックを整数倍に逓倍する回路です。入力 ÷ PLLM × PLLN ÷ PLLP という計算式でターゲット周波数を生成します。16MHz ÷ 16 × 336 ÷ 4 = 84MHz です。STM32CubeIDE の「Clock Configuration」タブを開くと、この経路がグラフィカルに表示されます。
STM32 には内部RC(HSI)と外部水晶(HSE)の2種類のクロックソースがあります。HSI は外付け部品不要で手軽ですが、温度や個体差で±1%程度の誤差があります。HSE は水晶の精度(±20ppm 程度)が出るため UART や USB などで正確な周波数が必要なときに使います。どちらを使っても 84MHz の SYSCLK が出せるので、今回の計測実験には影響しません。
実際に何MHzで動いているかは、IDE やコードで確認できます。STM32CubeIDE の場合は Clock Configuration ビューで視覚的に確認できます。
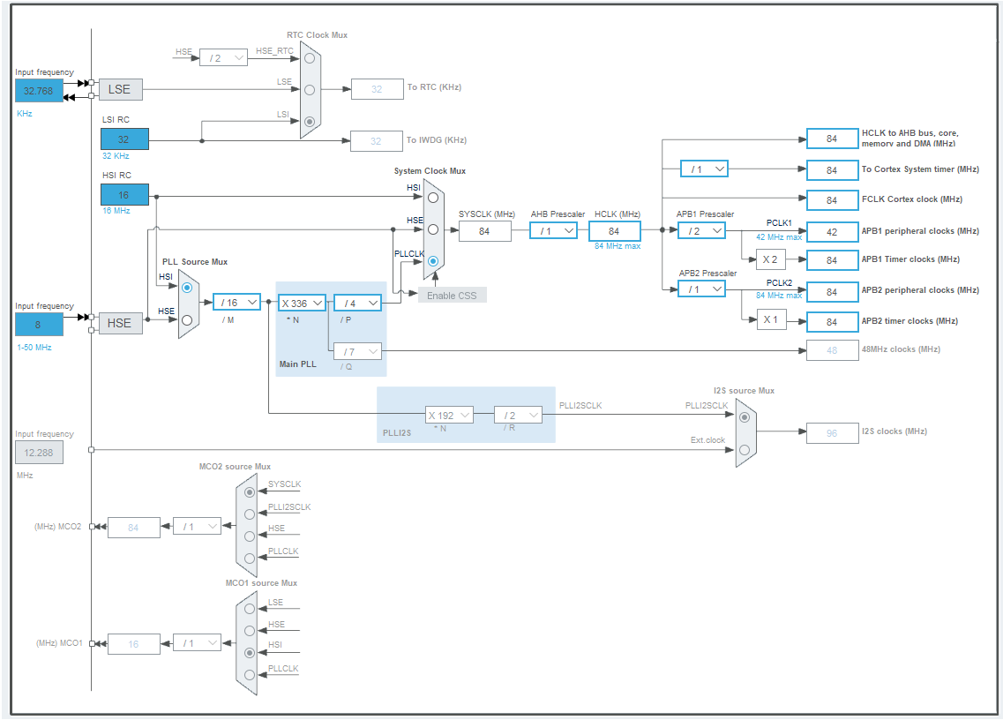
STM32CubeIDE の Clock Configuration ビュー。HCLK が 84MHz に設定されているのを確認する
CMSIS 準拠の環境では SystemCoreClock 変数に実際のクロック周波数(Hz)が格納されています:
uint32_t freq = SystemCoreClock; // 84000000
(void)freq;
// デバッガの Variables ビューで確認
計測マクロの 84U はこの値を根拠にしています。
光は1ns で約30cm進みます。1サイクル(≈12ns)の間に光が進む距離は 約3.6m です。84MHz の CPU にとって、3.6m 歩く時間が「最小の1歩(1サイクル)」です。その一歩ごとに1つの命令を終えています。組み込みの「速さ」がどれほどのスケールか、少し実感できるでしょうか。
「1命令 = 1サイクル」は厳密ではない
感覚値の表を見て「ならば全部の命令を数えれば正確な時間が出る」と思うかもしれません。ところがそう簡単ではありません。
現代のマイコンは Flash(プログラムを格納する不揮発メモリ)の読み出し速度がCPUのクロックに追いつかないため、命令を読む際に数サイクルの待ちが入ることがあるのです。
CPU が Flash から命令を読む場合:
サイクル 1 2 3 4 5
CPU : |命令読| 実行 |命令読| 実行 |...
Flash: |遅い!|遅い!|
→ Flash が間に合わず CPU が空白時間を待つ
これを防ぐため、ほとんどのマイコンは 命令キャッシュ を持っています。一度読んだ命令はキャッシュに保存され、次回からは待ちなしで実行できます。
実際の挙動はこうなります:
- 直線的に実行されるコード(ループ内など)→ キャッシュが効いてほぼ 1命令 ≈ 1サイクル
- 分岐・ジャンプ・割り込みエントリ→ キャッシュミスが起き、数サイクルのペナルティが加わる
| 状況 | 1命令あたりのサイクル数 | 原因 |
|---|---|---|
| 理想状態(直線コード) | ≈ 1 cycle | 命令キャッシュが完璧に効いている |
| 分岐・ジャンプ発生時 | 1 + α cycle | パイプラインの乱れ(分岐予測ミス) |
| Flash 待ち発生時 | 1 + 数 cycle | メモリ読み出しの遅延(Wait State) |
| 割り込みエントリ | +12〜数十 cycle | コンテキスト保存(レジスタ退避)のオーバーヘッド |
「このループは 1000サイクルのはず」と計算しても、実測が 1010〜1050サイクルになることがあります。キャッシュミスや割り込みオーバーヘッドが加わるためです。精度が必要なときこそ計算ではなく計測する——それが DWT CYCCNT を使う理由です。
84MHzでの感覚値:
| 処理 | サイクル数(目安) | 時間(目安) |
|---|---|---|
単純な加算(a + b) |
1〜2 | 約 12〜24 ns |
| RAM 読み出し | 1〜数 | 約 12〜60 ns |
| Flash 読み出し(ART キャッシュあり) | 1〜5 | 約 12〜60 ns |
GPIO 操作(HAL_GPIO_WritePin) |
約 10〜20 | 約 120〜240 ns |
| SPI 8bit 転送(1MHz クロック) | 約 8,000 | 約 8 µs |
| UART 1バイト(115200bps) | 約 730 | 約 87 µs |
HAL_Delay(1) (1ms待機) |
約 84,457 | 約 1,005 µs |
HAL_Delay(1000) (1秒待機) |
約 84,000,000 | 約 1,000 ms |
これらはすべて 「計測して初めて分かる数字」 です。1行の C コードが何サイクルかは、コンパイラの最適化・命令キャッシュ・メモリアクセスパターンによって変わります。だから 計測が必要 なのです。
⏰ 組み込みで使える「時間の道具」
組み込みで実行時間を測る方法は大きく3つあります。それぞれ分解能と用途が異なります。
| 方法 | 分解能 | 最大計測時間 | 用途 |
|---|---|---|---|
| msティックカウンタ(HAL_GetTick・millis など) | 1 ms | 約49日(32bit) | 大まかな時間管理・タイムアウト |
| サイクルカウンタ(DWT CYCCNT・ESP32 cycle count など) | 1サイクル(≒数〜十数 ns) | 数十秒(32bit) | µs〜ms単位の精密計測 |
| GPIOトグル+オシロ | オシロの分解能次第 | 制限なし | 実機での波形確認 |
どのマイコンにもこの3種類に相当する手段があります。名前や API は違っても、考え方は共通です。
ms ティックカウンタの限界
「起動してから何ミリ秒経ったか」を返す関数はどのプラットフォームにもあります。
| プラットフォーム | 関数 |
|---|---|
| STM32 HAL | HAL_GetTick() |
| Arduino / ESP32 Arduino | millis() |
| ESP-IDF | esp_timer_get_time() (µs単位) |
| Renesas RA (FSP) | R_BSP_SoftwareDelay() / SysTick カウント |
いずれも使いやすいですが、1ms より短い時間は測れない という限界があります。
/* STM32 の例(他プラットフォームでも考え方は同じ)*/
uint32_t start = HAL_GetTick(); // ms 単位
do_something();
uint32_t elapsed = HAL_GetTick() - start;
1ms以内で完了する処理(SPI転送・演算ループなど)を計測しようとすると、elapsed = 0 になってしまいます。µs 単位が必要なときは次のサイクルカウンタを使います。
Cortex-M に内蔵されたダウンカウンタです。設定した値からカウントダウンし、0になると割り込みを発生させます。STM32 HAL・Arduino・FreeRTOS など多くのフレームワークがこれを 1ms 周期で使っています。HAL_GetTick() や millis() はその割り込みごとにインクリメントされるカウンタを返しているだけです。
🔬 DWT CYCCNT ― サイクル単位の計測器
DWT(Data Watchpoint and Trace)とは
DWT は Cortex-M に内蔵されたデバッグ・トレース用のハードウェアユニットです。その中に CYCCNT(Cycle Counter) という32bitカウンタがあり、CPUクロックに同期して毎サイクルインクリメントします。
DWT の詳細は STM32 のリファレンスマニュアル(RM0xxx)には載っていません。ARM 公式の 『Cortex-M4 Devices Generic User Guide』 または 『ARM v7-M Architecture Reference Manual』 に記載されている、Cortex-M シリーズ共通の仕様です。STM32 に限らず Cortex-M を搭載したすべてのマイコンに適用されます。
printf デバッグとの決別
「実行時間を調べたいとき、とりあえず printf を挿れて確認する」——組み込みあるあるの罠です。
// ❌ printf で計測しようとした場合
printf("start\n");
do_something();
printf("end\n");
// → printf 自体が UART 送信のため数万〜数十万サイクル消費する
// 計測したかった処理より printf の方が重く、意味のない結果になる
これは 観測者効果(計測行為そのものが対象を変えてしまう)の典型例です。115200bps の UART で1バイト送るだけで約730サイクル。"start\n" の6文字で 約4,400サイクル が消えます。
DWT CYCCNT はレジスタを1回読むだけなので、オーバーヘッドは わずか数サイクル です。「計測によって計測対象を壊さない」——これが DWT を使う最大の理由の一つです。
実際に計測できます:
uint32_t s = DWT_START();
uint32_t overhead = DWT_CYCLES(s); // この1行だけのコストを測る
overhead は通常 2〜4サイクル 程度です。これが計測の「物差しの誤差」の上限です。
DWT は ARM が Cortex-M に内蔵しているデバッグ機能で、STM32 固有ではありません。Cortex-M0+ 以上のマイコン(nRF52、RP2040、Renesas RA、SAM など)で同じコードが動きます(Cortex-M0 には CYCCNT がないため不可)。
Cortex-M 以外でも同等のサイクルカウンタがあります:
- ESP32(Xtensa):
xthal_get_ccount()またはesp_cpu_get_cycle_count() - AVR(Arduino Uno):ハードウェアカウンタなし。16bit タイマで代替
- RISC-V(ESP32-C3 など):
__builtin_riscv_rdcycle()
名前は違いますが「CPUクロックと同期してカウントする」という本質は同じです。
CYCCNTを有効化する
DWT は デフォルトで無効 です。使う前に有効化が必要です。
/* DWT CYCCNT を有効化する(一度だけ呼べばOK) */
void DWT_Init(void)
{
/* ① CoreDebug の DEMCR レジスタで DWT を有効化 */
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk;
/* ② CYCCNT をリセット */
DWT->CYCCNT = 0;
/* ③ CYCCNT カウントを開始 */
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk;
}
DEMCR(Debug Exception and Monitor Control Register)は CoreDebug のレジスタで、デバッグ機能の有効/無効を制御します。TRCENA(Trace Enable)ビットを 1 にすることで DWT・ITM などのトレースユニットが動作するようになります。このビットが 0 のままだと DWT->CYCCNT は常に 0 になります。 「計測してるのに常に 0」というときはここを疑ってください。
また、デバッガを接続した状態では動くのに、単体(デバッガなし)で電源を入れると常に 0 になるというケースがあります。これはデバッグ機能へのクロック供給がデバッガ接続時のみ有効になる環境で起きます。DWT_INIT() を必ずコード内で呼んでいることを確認してください。
Cortex-M7 系(STM32H7 など上位機種)に移行する際は、DWT->LAR = 0xC5ACCE55; というアンロック操作が必要になる場合があります。F401RE(Cortex-M4)では通常不要ですが、移植時の定番として覚えておくと役立ちます。
計測マクロを作る
毎回レジスタを直接操作するのは煩雑なので、計測用マクロを用意します。#define はコードではなくプリプロセッサ指令なので、/* USER CODE BEGIN PD */(Private Define セクション)に書くのが適切です。CubeMX が再生成しても消えません。
/* main.c の USER CODE BEGIN PD に書く */
/* DWT CYCCNT 初期化 */
#define DWT_INIT() do { \
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk; \
DWT->CYCCNT = 0; \
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk; \
} while(0)
/* 計測開始・終了 */
#define DWT_START() (DWT->CYCCNT)
#define DWT_CYCLES(start) (DWT->CYCCNT - (start))
/* サイクル数 → µs 変換
* CYCLES_TO_NS と同様に 64bit で計算することで、
* 超低速クロック(< 1MHz)での (SystemCoreClock / 1000000U) = 0 によるゼロ除算を回避。 */
#define CYCLES_TO_US(cycles) ((uint32_t)((uint64_t)(cycles) * 1000000ULL / SystemCoreClock))
/* サイクル数 → ns 変換
* 1ns = 1/10^9 s なので、cycles / SystemCoreClock * 10^9 = cycles * 10^9 / SystemCoreClock
* 64bit で計算することで (cycles * 10^9) のオーバーフローを回避し、
* かつ超低速クロック(< 1MHz)でのゼロ除算も起きない。 */
#define CYCLES_TO_NS(cycles) ((uint32_t)((uint64_t)(cycles) * 1000000000ULL / SystemCoreClock))
マクロを複数文に展開するとき do { ... } while(0) で囲むのは C の慣用句です。if (x) DWT_INIT(); のような文の中でも正しく動作します。知らなくても使えますが、GCC の警告を抑えるためにも推奨される書き方です。
CYCLES_TO_US / CYCLES_TO_NS ともに SystemCoreClock を直接使う式にそろえています。84MHz 固定の環境では cycles / 84 や cycles * 1000 / 84 と直書きしても同じ結果ですが、変数版はクロック設定を変えても修正不要で、超低速クロック(< 1MHz)でのゼロ除算も起きません。
📐 実測してみる
実験1:HAL_Delay(1) は何サイクルか
HAL_Delay(1) は「1ms待つ」関数です。84MHz では理論上 84,000 サイクル のはずです。実際に計測してみましょう。
USER CODE BEGIN 2 に以下を書いてデバッグ実行します:
/* USER CODE BEGIN 2 */
DWT_INIT(); // DWT を有効化(必ず最初に呼ぶ)
/* --- 単発計測 --- */
uint32_t start = DWT_START();
HAL_Delay(1); // 1ms 待機(何サイクルか?)
uint32_t cycles = DWT_CYCLES(start);
uint32_t us = CYCLES_TO_US(cycles);
/* デバッガの Variables ビューで cycles と us を確認 */
(void)cycles;
(void)us;
/* --- 複数回計測してばらつきを確認 --- */
uint32_t results[10];
for (int i = 0; i < 10; i++) {
uint32_t s = DWT_START();
HAL_Delay(1);
results[i] = DWT_CYCLES(s);
}
/* Variables ビューで results 配列を確認 */
/* USER CODE END 2 */
results 配列の末尾にブレークポイントを置き、Variables ビューで配列を展開して確認します。
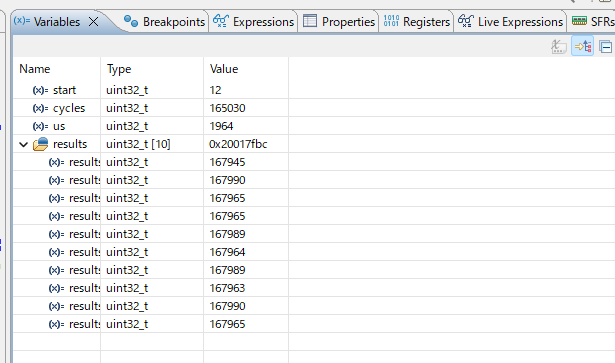
Variables ビューで cycles・us・results 配列を確認。HAL_Delay(1) が実際に何サイクル使っているかが数値で見える
HAL_Delay(1) は「HAL_GetTick() が 1 以上増えるまでポーリング」する実装です。SysTick は 1ms ごとに割り込んでカウンタを更新しますが、関数を呼んだ瞬間がその周期のどこにあるかによって待ち時間が変わります。
- tick 直前に呼んだ場合:すぐ次の tick を捕まえるので ≈ 84,000〜85,000 cycles(≒ 1ms)
- tick 直後に呼んだ場合:次の tick まで約 1ms 待ってさらにその次まで待つので ≈ 168,000 cycles(≒ 2ms)
つまり HAL_Delay(1) の実態は「1ms〜2ms のどこかで返ってくる」です。
実測値(NUCLEO-F401RE, 84MHz, -O0):
HAL_Delay(1) の計測結果(10回計測、ほぼ固定)
cycles ≈ 167,965 (≒ 1,999 µs ≈ 2 ms)
us ≈ 1999
計測ばらつき:167,945〜167,990(約45サイクル ≈ 0.5 µs)
この環境では起動シーケンスの長さが毎回ほぼ一定で、HAL_Delay(1) に到達するたびに SysTick 直後という同じ位相に当たっています。結果としてほぼきっかり 2ms 待つ動作になっています。
呼び出しタイミングによっては 84,000〜168,000 cycles(1〜2ms) の範囲に収まります。これが「N ms 以上 待つ」の意味です。
HAL_Delay(N) は「N ms 以上 待つ」であり、ぴったり N ms とは限りません。厳密なタイミング制御に使うのは危険です。第8回の割り込みで代替手段を学びます。
実験2:演算ループの実行時間を測る
実験1では「待機」の時間を測りました。次は「実際に CPU が計算しているコード」の時間を測ります。
HAL_Delay のような「何もしない待ち」ではなく、自分が書いたロジックが何サイクル消費しているかを知ることが、組み込みでのボトルネック特定の出発点です。
/* 計測対象:簡単な演算ループ */
uint32_t start = DWT_START();
uint32_t sum = 0;
for (int i = 0; i < 1000; i++) {
sum += i;
}
uint32_t cycles = DWT_CYCLES(start);
uint32_t us = CYCLES_TO_US(cycles);
(void)sum;
(void)cycles;
(void)us;
実測値(NUCLEO-F401RE, 84MHz, -O0):
for ループ 1000回(-O0)
sum = 499500 (0+1+...+999 の正しい結果)
cycles = 16018 (≒ 190 µs)
us = 190
16,018サイクル ÷ 84MHz = 約 190µs。「1000回ループなんて一瞬だろう」と思っていても、デバッグビルドでは 190µs かかっています。これが「計測しないと分からない」の意味です。
次の実験3でリリースビルドと比べると、この数字が劇的に変わります。
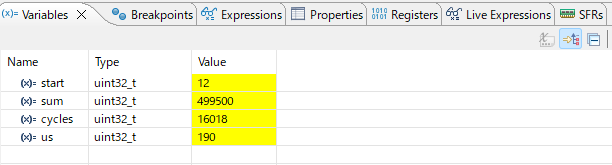
Variables ビューで cycles と us を確認。1000回ループが 16,018サイクル(約 190µs)かかっていることが数値で見える
ループ回数を 1000 から 10000 に変えて計測してみてください。サイクル数はほぼ10倍になるはずです。ならなければ何かが起きています——何でしょうか?
実験3:最適化レベルで何が変わるか
第6回では「最適化でコードが消える」と説明しました。今回は その効果をサイクル数という実数で確認します。
コードは実験2と同じですが、すべての変数に volatile を付けてコンパイラが値を最適化で消せないようにします:
volatile uint32_t start = DWT_START();
volatile uint32_t sum = 0;
for (int i = 0; i < 1000; i++) {
sum += i;
}
volatile uint32_t cycles = DWT_CYCLES(start);
volatile uint32_t us = CYCLES_TO_US(cycles);
Release ビルド(-O2)では、デバッガで参照されない変数はレジスタに置かれたまま Variables ビューに表示されません。volatile を付けると RAM への書き出しが強制され、デバッガから値が見えるようになります。ただし sum 自体を volatile にするとループの毎イテレーションで RAM アクセスが発生し、最適化の効果が正しく計測できなくなります。今回は「計測結果を見たい」目的なので全変数に付けています。
Release ビルドへの切り替え手順(STM32CubeIDE):
- Project Explorer でプロジェクトを右クリック → Build Configurations → Set Active → Release
- Project → Properties → C/C++ Build → Settings → MCU GCC Compiler → Debugging → Debug level を
-g2に設定(ソース対応付けに必要) - Project → Clean… → Clean all
- Ctrl+B でリビルド
- Run → Debug Configurations → 「C/C++ Application」欄を
Release/プロジェクト名.elfに変更 - デバッグ実行
実測値(NUCLEO-F401RE, 84MHz):
| ビルド | cycles | us | 説明 |
|---|---|---|---|
| Debug(-O0) | 16,018 | 190 | ループを忠実に実行 |
| Release(-O2) | 8,011 | 95 | 最適化が効いて約半分 |
-O2 でも volatile のせいで毎イテレーション RAM 読み書きが発生するため、完全には消えずに 8,011サイクルになっています。
volatile をすべて外した -O2 では、sum の結果が外部に使われないとコンパイラが判断し、ループごと削除します。cycles は数サイクル〜十数サイクルになります。これが第6回で説明した「最適化でコードが消える」の実態です。
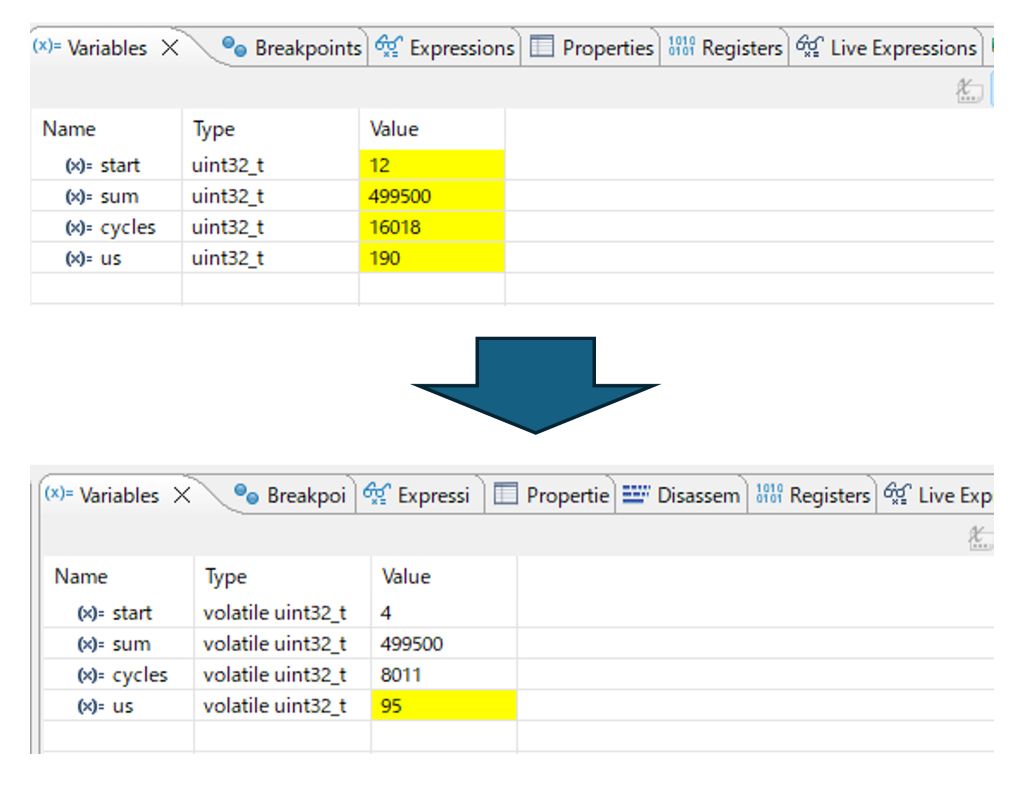
-O0(左)と -O2(右)のサイクル数比較。最適化の効果が数値として見える
感覚値の表にある HAL_GPIO_WritePin を計測してみてください。「約 10〜20サイクル」という値が実際に出るか確認してみましょう。
🔌 GPIOトグル+オシロスコープで測る
DWT CYCCNT はデバッガを使う方法ですが、実機で動かしながら波形を見たい 場合は GPIO トグルが有効です。
やり方
/* 計測開始:GPIO を High に */
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_5, GPIO_PIN_SET);
/* ← ここで計測したいコードを実行 → */
uint32_t sum = 0;
for (int i = 0; i < 1000; i++) {
sum += i;
}
(void)sum;
/* 計測終了:GPIO を Low に */
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_5, GPIO_PIN_RESET);
任意の GPIO ピンにオシロスコープ(またはロジックアナライザ)を当て、High になっている時間を測ります。STM32 なら PA5(ユーザーLED)が手軽です。Arduino なら digitalWrite()、ESP-IDF なら gpio_set_level() に置き換えるだけで同じ手法が使えます。
GPIO 操作の関数自体も数サイクル消費します。計測したいコードが短い場合、そのオーバーヘッドが無視できなくなります。µs 以下の精度が必要なときはサイクルカウンタを使い、ms オーダーの動作確認に GPIO トグルを使いましょう。
⚠️ DWT CYCCNT の注意点
オーバーフロー
CYCCNT は 32bit カウンタ です。84MHz では 約51秒でオーバーフロー(0に戻る)します。
2^32 ÷ 84,000,000 Hz ≈ 51.1 秒
51秒以内に完了する処理なら問題ありません。ただし long-running な処理の計測では、差分が正しく計算されます(符号なし整数の減算はラップアラウンドを正しく処理する):
uint32_t cycles = end - start; // start > end (overflow) でも正しく差分が出る
// ただし計測区間が 51秒以内である必要がある
デバッグビルド限定ではない
DWT CYCCNT はリリースビルドでも使えます。デバッガなしの実機でも動作します。(void)cycles を消して UART や LED で出力することも可能です。
割り込みが入ると増える
計測中に割り込みが入ると、その分のサイクルも CYCCNT に加算されます。精密な計測では割り込みを一時的に無効にすることを検討してください:
__disable_irq(); // 割り込み禁止
uint32_t start = DWT_START();
/* 計測したいコード */
uint32_t cycles = DWT_CYCLES(start);
__enable_irq(); // 割り込み再有効
__disable_irq() 中は SysTick 割り込みも止まる ため、HAL_GetTick() のカウントが進みません。禁止区間中に HAL_Delay() を呼ぶと永久ループになります。割り込み禁止はできるだけ短く(数µs以内)、その区間に HAL のタイムアウト系 API を呼ばないよう注意してください。
🏭 実用シナリオ:計測で何を見つけるか
DWT CYCCNT は「計測のためだけのおもちゃ」ではありません。実際の開発で次のような場面で使います。
シナリオ1:「この ISR は間に合っているか?」
ISR(Interrupt Service Routine) とは、割り込みが発生したときに自動的に呼ばれる処理関数です。詳細は第8回で扱いますが、「一定時間ごとに呼ばれる処理」と理解しておけば十分です。
1ms タイマ割り込みの中で処理をしている場合、ISR の実行時間が 1ms を超えてはいけません(次の割り込みに間に合わない)。
void TIM2_IRQHandler(void)
{
uint32_t start = DWT_START();
/* 割り込みハンドラの処理 */
HAL_TIM_IRQHandler(&htim2);
do_some_work();
uint32_t cycles = DWT_CYCLES(start);
/* cycles が 84,000 を超えていたら処理が重すぎる */
if (cycles > 84000) {
/* エラー処理・警告LED など */
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_5, GPIO_PIN_SET);
}
}
シナリオ2:「SPI 通信は何µs かかるか?」
SPI でセンサーからデータを読む処理の時間を計測する例:
uint32_t start = DWT_START();
HAL_SPI_TransmitReceive(&hspi1, tx_buf, rx_buf, 4, HAL_MAX_DELAY);
uint32_t cycles = DWT_CYCLES(start);
uint32_t us = CYCLES_TO_US(cycles);
/* us に実際の SPI 転送時間が入る */
SPI クロック 1MHz で 4バイト転送なら理論値は 32µs。実測で 35µs だったとすれば、HAL オーバーヘッドが 3µs あることが分かります。
シナリオ3:「ボトルネックはどこか」を特定する
大きな処理を計測するとき、部分ごとに計測して比較する ことでボトルネックを特定できます:
uint32_t t0 = DWT_START();
step_A();
uint32_t t1 = DWT_START();
step_B();
uint32_t t2 = DWT_START();
step_C();
uint32_t t3 = DWT_START();
uint32_t cyc_A = t1 - t0;
uint32_t cyc_B = t2 - t1;
uint32_t cyc_C = t3 - t2;
/* どのステップが一番重いかが数値で分かる */
「たぶん step_B が重い」ではなく、「step_B は 1,200サイクル、step_C は 200サイクル」 と言えるようになる——これが計測文化です。
| 状況 | 使う方法 |
|---|---|
| タイムアウト・ms 単位の遅延 | ms ティックカウンタ(HAL_GetTick / millis など) |
| µs〜ms 単位の精密計測 | サイクルカウンタ(DWT CYCCNT / esp_cpu_get_cycle_count など) |
| 実機での波形確認・ms オーダー確認 | GPIO トグル+オシロ/ロジアナ |
| 超短時間・割り込みなし環境 | サイクルカウンタ + 割り込み禁止 |
「計測してから議論する」という文化
組み込みエンジニアの世界では、「たぶん速い」「たぶん間に合う」は通用しません。
- 「このループは何µsかかるか?」→ 計測してから答える
- 「最適化で速くなったか?」→ 計測して前後を比較する
- 「割り込みの応答時間は大丈夫か?」→ 計測して確認する
DWT CYCCNT はそのための最初の道具です。今回身につけた計測の習慣は、第8回以降の割り込み・DMA・RTOS を学ぶときにも必ず使います。
まとめ
今回学んだこと:
- クロック周波数 → NUCLEO-F401RE は 84MHz。1サイクル ≈ 12ns
- HAL_GetTick() → 1ms 分解能。タイムアウト・遅延管理に適する
- DWT CYCCNT → 1サイクル分解能。µs単位の精密計測に最適
- GPIOトグル → オシロで波形確認。ms オーダーの実機確認に手軽
- 計測文化 → 「たぶん」ではなく「計測した値」で議論する
何が遅いかを知らずに最適化しても、間違った場所を速くするだけです。まず計測し、ボトルネックを特定し、そこだけ最適化する——これが組み込みプロの作法です。(Donald Knuth の言葉を組み込みに適用)
次回は 「割り込みとは何か」 に入ります。「時間の世界」を 能動的に支配する ための核心技術です。
次回予告
⚡ 第8回:割り込みとは何か(NVIC/ベクタ/怖さ)
「1ms ごとに何かをする」ためにポーリングでは何が問題か? ベクタテーブル・NVIC・コンテキスト保存の仕組みを理解し、TIM割り込みで周期イベントを生成します。