はじめに
ℹ️ 前回の記事
👉 ESP32-S3からAzureへデータを飛ばす!HTTPS POSTとサーバーレス連携の極意
(Azure FunctionsへのHTTPS/JSON通信の実装方法を解説しています)
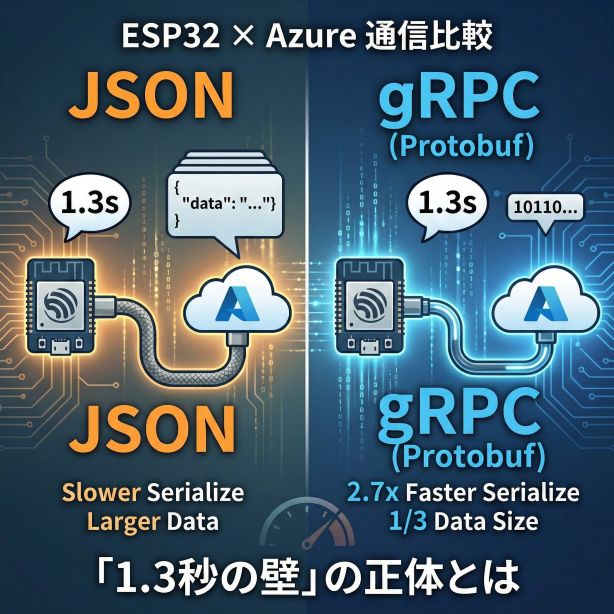
前回、Azure FunctionsへJSONデータを送信することに成功しました。しかし、そこで直面したのは「たった数個のデータを送るのに、なぜこんなに通信が重いのか?」という疑問です。
今回は、その解決策となる gRPC / Protocol Buffers (Protobuf) の概念を、わかりやすく解説します。
1. JSONは「無駄」が多い? — データ構造の比較
HTTP/JSON通信は便利ですが、リソースの限られたマイコンにとっては非常に非効率な形式です。なぜ非効率なのか、具体的なデータサイズを見ながら理解していきましょう。
JSON:説明書付きの巨大な段ボール
JSONは人間にとって読みやすいテキスト形式ですが、これが逆にデータサイズを大きくする原因になっています。
JSONは、データと一緒に「そのデータが何であるか」という説明(キー文字列)を毎回送ります。例えば、温度と湿度のセンサーデータを送る場合を考えてみましょう。
- 例:
{"temp": 24.8, "humi": 55, "id": "ESP32-S3"} - 実際のバイト数: この文字列は約45バイトになります
- 無駄な部分:
"temp"や"humi"というキー名、クォーテーション、コロン、カンマなどの記号類がすべてバイト数を消費します - 問題点: 同じセンサーから1時間に1回データを送るだけでも、1日で約1KBのデータ量になります
さらに、JSONはテキスト形式なので数値も文字列として送られます。例えば 24.8 という数値は、バイナリなら4バイトで済むところを、4文字分(4バイト)のテキストとして送信されるのです。
Protobuf:中身を知っている者同士の「真空パック」
Protobuf(Protocol Buffers)は、Googleが開発したバイナリ形式のデータフォーマットです。事前に「設計図(.proto)」を共有することで、説明書きをすべて削ぎ落とします。
- 仕組み: 「1番目のデータは温度(float型)」「2番目は湿度(int型)」「3番目はデバイスID(string型)」というルールを双方が知っているため、実際の通信ではバイナリデータのみを並べて送ります
- データの持ち方: JSONの
{"temp": 24.8}が、Protobufでは[0x0D, 0x00, 0x00, 0xC6, 0x41]のような数バイトのバイナリになります - 結果: 同じ内容でもサイズは 1/3以下 に圧縮されます。先ほどの45バイトのJSONデータが、Protobufなら15〜20バイト程度で済みます
この差は、バッテリー駆動のIoTデバイスにとって非常に重要です。データ量が減れば送信時間が短くなり、その分電力消費も削減できるのです。
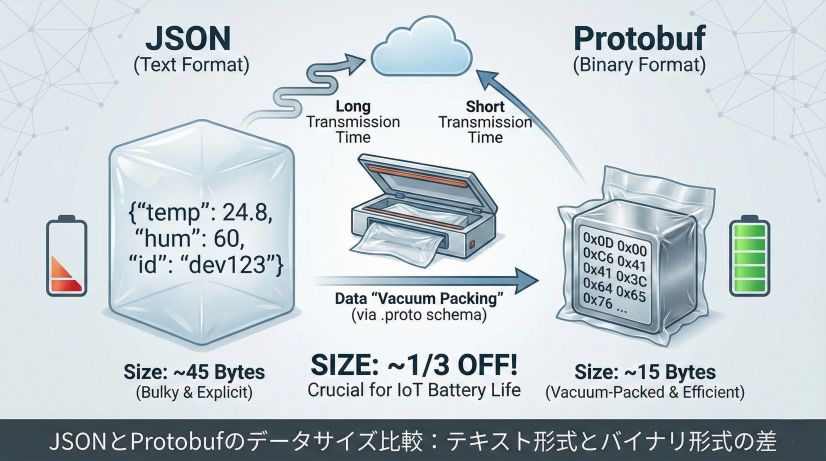
JSONとProtobufのデータサイズ比較:テキスト形式とバイナリ形式の差
2. なぜ「1バイト」の節約が、ESP32の寿命を変えるのか
「たかだか数十バイトの差なんて…」と思うかもしれません。しかし、マイコンにおいてこの差は 「電気代(寿命)」 に直結します。特にバッテリー駆動のIoTデバイスでは、データサイズの最適化が動作時間を左右する重要な要素なのです。
電力消費の直結:送信時間=電力消費
ESP32のWi-Fi通信における電力消費を理解するには、次の3つのフェーズを知る必要があります。
- スリープモード: 約10μA(ほとんど電力を使わない)
- Wi-Fi接続中: 約80〜170mA(接続を維持するだけで電力を消費)
- データ送信中: 約240mA(最も電力を消費)
Wi-Fiチップが電波を飛ばす時間は、送信データ量に比例します。45バイトのJSONを送るのと、15バイトのProtobufを送るのでは、送信時間が約3倍違います。つまり、電波を飛ばしている時間(=高電力状態の時間)が3分の1になるのです。
パケットが小さければ送信時間は短くなり、それだけ早く Deep Sleep に戻れます。例えば、1日100回データを送信するセンサーの場合:
- JSON(45バイト): 送信時間 約3秒 × 100回 = 300秒/日
- Protobuf(15バイト): 送信時間 約1秒 × 100回 = 100秒/日
この差が積み重なると、バッテリー寿命が数ヶ月単位で変わってくるのです。
メモリの断片化防止:安定動作の鍵
ESP32のRAMは限られています(ESP32-S3でも約520KB)。この限られたメモリを効率的に使うことが、安定動作の鍵となります。
cJSON 等によるJSON処理では、文字列の動的な生成と解析が必要です。これには以下の問題があります:
- 動的メモリ確保: JSONパース時に何度も
malloc()/free()が呼ばれ、メモリが断片化します - 文字列操作のオーバーヘッド:
"temperature"という文字列を毎回検索してパースする必要があります - 予測不可能なメモリ使用量: JSONの構造が複雑になると、必要なメモリ量が読めません
バイナリ処理のProtobufは、メモリ消費が予測可能で安定します:
- 固定サイズのバッファ: 事前にメモリを確保できるため、断片化が起きません
- 直接アクセス: 「1番目のフィールドは温度」と決まっているため、文字列検索が不要です
- スタック上で処理可能: 小さなデータなら動的メモリ確保すら不要になります
これにより、長時間稼働してもメモリ不足でフリーズすることがなくなります。
3. RPC と gRPC の違いを整理する
「通信」といえばHTTPやREST APIが有名ですが、RPCはそれらとは少し毛色が違います。まずは、RPCという考え方の基本から理解していきましょう。
RPC(Remote Procedure Call)とは?
直訳すると「遠隔手続き呼出し」です。これは1980年代から存在する古典的な通信の考え方ですが、その本質は今でも非常に強力です。
通常、ネットワーク通信を書くときは次のような手順を踏みます:
// 従来のHTTP通信(REST API)
1. HTTPクライアントを初期化
2. URLを構築("https://example.com/api/sensor")
3. HTTPヘッダーを設定(Content-Type: application/jsonなど)
4. JSONデータを文字列に変換
5. POSTリクエストを送信
6. レスポンスを受信
7. JSONをパースして結果を取得
これだけのステップを毎回書くのは大変です。しかし、RPCの考え方はもっと直感的です。
「ネットワークの向こう側にある関数を、自分の手元の関数と同じ感覚で呼び出す」。これがRPCの核心です。
// RPCの理想的な形
SensorData data = {24.8, 55, "ESP32-S3"};
Response response = remote_send_sensor_data(&data); // ←これだけ!
まるでローカルの関数を呼んでいるかのように、ネットワーク通信ができる。これがRPCの魅力です。通信の詳細(HTTPメソッド、ヘッダー、シリアライズなど)はすべてフレームワークが自動で処理してくれます。
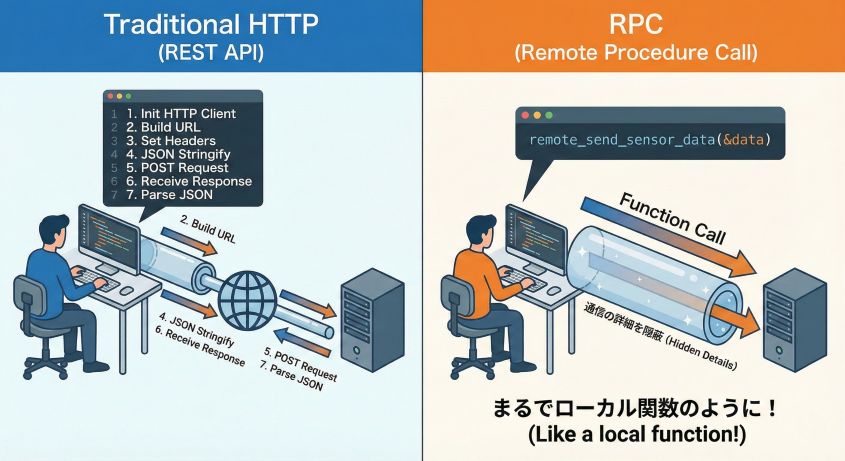
RPCの概念:ネットワークを越えた関数呼び出し
gRPC とは?
このRPCという考え方を、Googleが最新技術で「超高速・超軽量」に作り替えたのが gRPC です。gRPCの「g」は「Google」を意味していますが、今では多くの企業で採用されています(Netflix、Uberなど)。
gRPCが従来のHTTP/JSON通信と何が違うのか、3つのポイントで比較してみましょう。
| 進化のポイント | 従来のHTTP/JSON | gRPC |
|---|---|---|
| 運搬方法 | HTTP/1.1 (1回ごとに接続を切る、遅い) | HTTP/2 (太いパイプを繋ぎっぱなし、速い) |
| データ形式 | JSON (人間が見やすいテキスト) | Protobuf (機械が読みやすいバイナリ) |
| 安全性 | ルーズ (中身が違っても実行まで気づかない) | 厳格 (設計図がないとビルドすらできない) |
運搬方法:HTTP/2の威力
HTTP/1.1では、リクエストを送るたびに接続を確立し直す必要がありました(Keep-Aliveを使っても制限があります)。これは、家に荷物を届けるたびに、配達員が倉庫と家を往復するようなものです。
HTTP/2では、一度接続を確立したら、その「太いパイプ」を通じて複数のリクエストを同時に流せます。さらに、ヘッダー圧縮やサーバープッシュなどの機能により、通信効率が大幅に向上します。
データ形式:バイナリの優位性
JSONはテキストなので、人間がブラウザで見て理解できます。しかし、機械同士の通信では、この「人間が読める」という特性は無駄でしかありません。
Protobufはバイナリ形式なので、機械が直接読み書きできます。パース(解析)の速度も、JSONの5〜10倍高速です。
安全性:型システムによる保護
REST APIでは、「このエンドポイントはどんなデータを受け付けるのか」という仕様がドキュメント(Swagger/OpenAPIなど)に書かれているだけです。実際にコードを実行するまで、データの型が合っているかわかりません。
gRPCでは、.proto ファイルという「設計図」が必須です。この設計図と違うデータを送ろうとすると、コンパイル時(ビルド時)にエラーになります。実行する前にミスに気づけるのです。
4. なぜ「gRPC」が最強なのか — 設計図(.proto)の力
gRPCの凄さは、「共通の設計図(.proto)」 を中心とした開発スタイルにあります。この設計図が、マイコン開発における多くの問題を解決してくれるのです。
ステップ1:設計図の共有
最初に「どんなデータを送り、どんな関数を呼ぶか」を .proto ファイルに書きます。これは一種の「契約書」のようなものです。
例えば、センサーデータを送る場合の .proto ファイルはこんな感じになります:
// sensor.proto
syntax = "proto3";
message SensorData {
float temperature = 1; // 1番目のフィールド:温度
int32 humidity = 2; // 2番目のフィールド:湿度
string device_id = 3; // 3番目のフィールド:デバイスID
}
service SensorService {
rpc SendData(SensorData) returns (Response); // データを送る関数
}
この .proto ファイルをESP32側とサーバー側の両方で共有します。これにより、双方が「どんなデータをやり取りするか」を完全に理解した状態で開発が始められます。
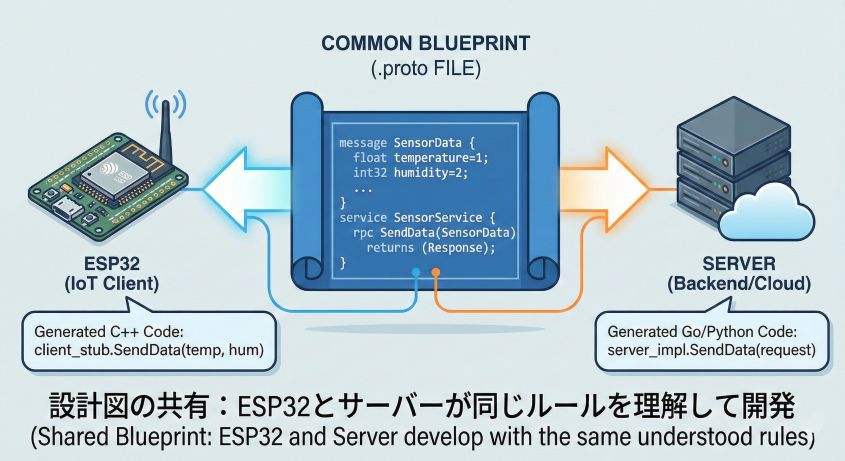
共通の設計図(.proto)を中心とした開発:ESP32とサーバーが同じルールを共有
重要なポイント:
- 言語非依存:
.protoファイルは言語に依存しません。C言語、Python、Go、JavaScriptなど、どの言語でも使えます - バージョン管理: この設計図をGitで管理すれば、データ構造の変更履歴が追跡できます
- ドキュメントとしても機能: コメントを書いておけば、それがそのままAPIドキュメントになります
ステップ2:コードの自動生成
この設計図を専用のツール(Protocol Buffers Compiler、通称 protoc)に通すと、各言語のプログラムが自動生成されます。
# ESP32(C言語)用のコード生成
protoc --nanopb_out=. sensor.proto
→ sensor.pb.h と sensor.pb.c が生成される
# サーバー(Python)用のコード生成
protoc --python_out=. sensor.proto
→ sensor_pb2.py が生成される
生成されたコードには、以下のものが含まれています:
- データ構造の定義: C言語なら
struct、Pythonならclassとして定義されます - シリアライズ関数: データをバイナリに変換する関数
- デシリアライズ関数: バイナリをデータに戻す関数
- 検証関数: データが正しいかチェックする関数
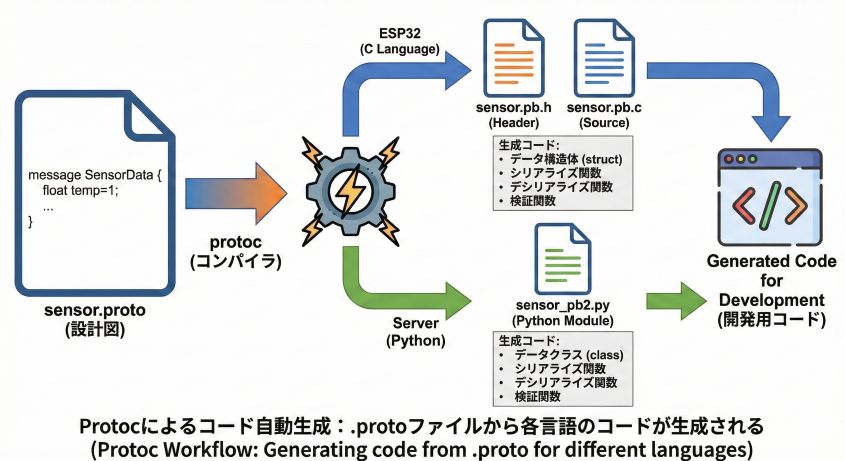
Protocによるコード自動生成:.protoファイルから各言語のコードが生成される
これが意味すること:
開発者は、シリアライズやデシリアライズのコードを一切書く必要がありません。設計図を書けば、面倒なバイナリ処理は全部ツールがやってくれるのです。
また、設計図を変更すれば、コードも自動で更新されます。例えば「気圧センサーを追加したい」と思ったら、.proto ファイルに float pressure = 4; を追加して、再度 protoc を実行するだけ。ESP32側もサーバー側も、自動的に新しいフィールドに対応したコードが生成されます。
5. マイコン(ESP32)でやるメリットと難易度
ここまでgRPCの良さを説明してきましたが、「実際にESP32で使うとどうなのか?」という疑問にお答えします。
メリット:型(型安全)で守られる
マイコン開発で一番怖いのは「データの型崩れ」です。特にJSON通信では、次のような悲劇がよく起こります。
よくある失敗例(JSON):
// ESP32側で送信(間違ってstring型で送ってしまった)
cJSON_AddString(json, "temperature", "24.8"); // ←数値なのに文字列!
# サーバー側で受信
temp = data['temperature'] * 1.8 + 32 # ←エラー!文字列と数値の演算
このミスは、実際に実行するまで気づきません。デバッグに数時間かかることも珍しくありません。
gRPCの場合:
// ESP32側(.protoでfloat型と定義されている)
SensorData data;
data.temperature = "24.8"; // ←ビルドエラー!float型にstringは入らない
gRPCでは、設計図(.proto)と違うデータを送ろうとすると、ビルドの時点でエラーになります。コンパイラが「型が合ってないよ!」と教えてくれるのです。
「動いているなら、通信形式は絶対に正しい」という安心感は絶大です。これは大規模なシステムになればなるほど、その価値が増していきます。
その他のメリット:
- ドキュメント不要:
.protoファイルが仕様書になるため、別途APIドキュメントを書く必要がありません - 後方互換性: フィールドを追加しても、古いバージョンのクライアントが壊れない仕組みが標準で備わっています
- 多言語対応: サーバーをPythonからGoに変更しても、
.protoファイルが同じなら通信コードの変更は不要です
難易度:リソース制限との戦い
良いことばかりに聞こえるgRPCですが、マイコンで使うには課題もあります。
gRPCは本来、Googleのデータセンター内の高性能サーバー間通信のために作られました。そのため、フル機能のライブラリ(grpc-c++など)はESP32には重すぎます。メモリも計算リソースも足りません。
そこで、マイコン向けに最適化された軽量版の 「nanopb」 を使います。nanopbは以下の特徴があります:
- 小さいフットプリント: フル版の1/100以下のメモリ使用量
- 動的メモリ不要: すべてスタック上で処理可能(malloc/freeが不要)
- C言語で実装: C++ではなくC言語なので、軽量で移植性が高い
ただし、制約もあります:
- フル機能のgRPCではない: HTTP/2やストリーミングは使えず、Protobufのシリアライズ機能のみ
- 手動でHTTP通信を実装: gRPCの「関数を呼ぶだけ」という理想形ではなく、自分でHTTPリクエストを組み立てる必要があります
最大の山場:
この「nanopb」をESP-IDFのビルドシステム(CMake)に組み込み、.proto ファイルから自動でC言語のコードを生成する環境を作るまでが、一番の難所になります。
具体的には:
- nanopbのライブラリをESP-IDFプロジェクトに追加
.protoファイルを配置- CMakeLists.txtにカスタムビルドルールを追加
- ビルド時に自動で
.proto→.pb.c/.pb.hを生成する仕組みを構築
このセットアップには、CMakeの知識とESP-IDFのビルドシステムの理解が必要です。しかし、一度環境を作ってしまえば、あとは .proto ファイルを編集するだけで、通信コードが自動生成される快適な開発環境が手に入ります。
まとめ:贅沢な通信を、小さなマイコンに
正直に言えば、ESP32でgRPCを動かすのは、JSONに比べれば初期セットアップに手間がかかります。CMakeの設定、nanopbの組み込み、自動生成の仕組み作りなど、最初の壁は決して低くありません。
しかし、一度環境を作ってしまえば、その後の開発は驚くほど快適になります:
- 圧倒的に軽い: データサイズは1/3以下、送信時間も短縮され、バッテリー寿命が伸びる
- 絶対に型が壊れない: ビルド時にエラーが出るため、実行時のトラブルが激減
- メンテナンスが楽: 新しいセンサーを追加したい?
.protoに1行書いて再ビルドするだけ - スケールしやすい: デバイスが10台になっても100台になっても、型安全性が開発を守ってくれる
さらに、この技術を身につければ、単なる趣味の電子工作ではなく、商用レベルのIoTシステムを設計できるようになります。実際、多くの企業が本番環境でgRPCを使っています。
「できるかどうか」ではなく、「やる価値があるから、やってみる」。 この「贅沢な挑戦」の先に、IoT開発の新しい景色が待っています。