はじめに
AI・機械学習やCAD作業を日常的に行う環境で、これまでNVIDIA RTX A4000(Ampere) を使用してきました。しかし、より大規模なモデルの学習や高解像度の画像生成作業が増えるにつれ、VRAM容量や処理速度の限界を感じるようになりました。
そこで、最新のRTX PRO 4000 Blackwell(GB203アーキテクチャ / 5nmプロセス)への換装を決意。本記事では、AI推論、画像生成、CAD、そしておまけでゲーム性能まで、詳細なベンチマーク結果をお届けします。
🖥 検証環境
システム構成
- CPU: AMD Ryzen 9 5900X(12コア / 24スレッド)
- メモリ: 64GB DDR4
- OS: Windows 11 Pro
- マザーボード: PCIe 5.0対応
主な用途
- AI・機械学習: LLMの推論実験、ファインチューニング
- 画像生成: Stable Diffusion / SDXL による高解像度生成
- CAD: 機械設計、3Dモデリング
- その他: データ解析、シミュレーション
📊 スペック比較
今回換装した2つのGPUのスペックを比較します。
| 項目 | RTX A4000 (Ampere) | RTX PRO 4000 Blackwell | 差異 |
|---|---|---|---|
| GPUアーキテクチャ | GA104 (8nm) | GB203 (5nm) | 微細化 |
| CUDAコア / シェーダー | 6,144基 | 8,960基 | +45.8% |
| VRAM容量 | 16GB GDDR6 | 24GB GDDR7 (Hynix) | +50% |
| メモリバス幅 | 256 bit | 192 bit | -25% |
| メモリ帯域幅 | 448 GB/s | 672.0 GB/s | +50% |
| 消費電力 (TDP/TGP) | 140W | 145W | +5W |
| PCIeインターフェース | Gen 4 x16 | Gen 5 x16 | 最新世代対応 |
注目ポイント
✅ CUDAコアが約1.5倍に増加 → 並列処理性能の大幅向上
✅ VRAM 24GBへ拡大 → 大規模モデルやSDXLの高解像度生成に余裕
✅ GDDR7メモリ採用 → メモリ帯域幅が1.5倍に向上
✅ PCIe 5.0対応 → 将来的なボトルネック解消
なぜRTX PRO 4000 Blackwellを選ぶのか:「1スロット厚」という革命
RTX PRO 4000シリーズの最大の存在意義は「1スロット厚」 という物理的制約にあります。GeForce RTX 4080/4090が3スロット以上を占有し、ハイエンドワークステーションGPUでさえ2スロット厚が標準となる中で、この薄型設計は以下のような圧倒的なメリットをもたらします。
🏢 省スペース・高密度構成のメリット
マイクロATXやSFF(Small Form Factor)への導入が容易
従来、ハイエンドGPUは大型筐体必須でしたが、RTX PRO 4000は小型PC環境でも24GB VRAMとBlackwellアーキテクチャの性能を享受できます。オフィスや研究室のスペース制約がある環境で特に有利です。
モデルバリエーションについて:
RTX PRO 4000 Blackwellには複数のフォームファクターが存在し、用途に応じて選択できます。
| モデル | スロット厚 | TDP | 補助電源 | 最適用途 |
|---|---|---|---|---|
| 標準モデル | 1スロット | 145W | 必要 | 絶対性能重視・マルチGPU構成 |
| SFFモデル | 2スロット | 約70W | 不要 | ワットパフォーマンス重視・省電力SFF筐体 |
💡 購入時の選択基準
- 絶対性能重視なら標準モデル(145W): 本記事のベンチマーク結果はすべてこのモデル。最高の処理速度を求める方、マルチGPU構成を考えている方に最適。
- ワットパフォーマンス重視ならSFFモデル(約70W): 消費電力が標準モデルの約半分でありながら、PCIe電源のみで駆動可能。電源容量が限られた小型筐体や、電力コストを抑えたい環境に理想的。補助電源ケーブル配線が不要で、小型ケース内の取り回しが容易。
どちらを選ぶべきか:
24時間稼働するAIサーバーや、電気代を気にする個人ユーザーならSFFモデルの省電力性が魅力的です。一方、レンダリング速度や推論速度を最大化したい場合は、標準モデル一択となります。
マルチGPU構成での拡張性
一般的なATXマザーボードであれば、1スロット厚を活かして2枚、3枚と並べることで「VRAM 48GB / 72GB環境」を省スペースで構築可能。これは、大規模言語モデルのファインチューニングや、複数の画像生成タスクを並列実行したいAIエンジニアにとって最大の魅力です。
例えば:
- 2枚構成(VRAM 48GB): Llama 70Bクラスの大規模モデルを量子化なしで推論可能
- 3枚構成(VRAM 72GB): SDXL複数インスタンス並列稼働、または超高解像度レンダリング
NVLinkによるVRAM統合
RTX PRO 4000 BlackwellはNVLink対応モデルです。NVLink接続を使用することで、複数GPUのVRAMを統合された単一のメモリプールとして扱うことが可能になります。これにより、PCIe経由での通信と比較して格段に高速なGPU間データ転送が実現し、大規模モデルの学習・推論時のボトルネックを大幅に軽減できます。
特に、単一GPU(24GB)では扱えない大規模言語モデルを、NVLinkで接続した2枚構成(48GB統合VRAM)で効率的に動作させられる点は、AIエンジニアにとって実用上の大きなメリットです。
GeForce RTX 4090では物理的に不可能なこの密度が、ワークステーションGPUとしてのRTX PRO 4000の真の価値と言えるでしょう。

RTX PRO 4000 Blackwell 実物(1スロット厚)
🤖 AI・機械学習ベンチマーク
テスト内容:Llama 3.1 8B 推論速度
Ollama(ローカルLLM実行環境)を使用し、Llama 3.1 8Bモデル(Meta社の大規模言語モデル、80億パラメータ)で同一プロンプトを5回連続実行。初動性能と連続稼働時の安定性を検証しました。
用語解説:
- t/s (tokens/sec): 1秒間に処理できるトークン(単語の最小単位)数。値が大きいほど高速。
- Prompt Eval: 入力テキストの理解・処理速度
- Eval: テキスト生成速度(実際の回答を生成する速度)
RTX A4000 (Ampere) 詳細ログ
| 試行 | Total Duration | Load Duration | Prompt Eval Count | Prompt Eval Duration | Prompt Eval Rate | Eval Count | Eval Duration | Eval Rate |
|---|---|---|---|---|---|---|---|---|
| #1 | 6.363s | 94.97ms | 30 tokens | 206.70ms | 145.14 t/s | 420 tokens | 5.865s | 71.61 t/s |
| #2 | 5.437s | 85.86ms | 479 tokens | 314.70ms | 1,522.09 t/s | 342 tokens | 4.857s | 70.41 t/s |
| #3 | 4.941s | 88.65ms | 850 tokens | 179.67ms | 4,730.82 t/s | 314 tokens | 4.522s | 69.43 t/s |
| #4 | 6.154s | 85.81ms | 1,192 tokens | 290.75ms | 4,099.73 t/s | 383 tokens | 5.607s | 68.31 t/s |
| #5 | 5.348s | 83.68ms | 1,604 tokens | 227.72ms | 7,043.66 t/s | 330 tokens | 4.882s | 67.60 t/s |
RTX PRO 4000 Blackwell 詳細ログ
| 試行 | Total Duration | Load Duration | Prompt Eval Count | Prompt Eval Duration | Prompt Eval Rate | Eval Count | Eval Duration | Eval Rate |
|---|---|---|---|---|---|---|---|---|
| #1 | 5.516s | 121.35ms | 135 tokens | 170.00ms | 794.27 t/s | 531 tokens | 4.964s | 106.96 t/s |
| #2 | 10.748s | 105.36ms | 694 tokens | 170.15ms | 4,078.87 t/s | 1,037 tokens | 10.005s | 103.65 t/s |
| #3 | 5.798s | 89.80ms | 1,759 tokens | 234.04ms | 7,515.66 t/s | 527 tokens | 5.220s | 100.96 t/s |
| #4 | 8.354s | 93.76ms | 2,314 tokens | 251.43ms | 9,203.27 t/s | 761 tokens | 7.651s | 99.47 t/s |
| #5 | 10.674s | 88.86ms | 3,103 tokens | 161.43ms | 19,222.33 t/s | 969 tokens | 9.945s | 97.43 t/s |
AI推論速度:Blackwellが最大5.47倍高速化
生成速度 (Eval Rate)
- A4000: 71.61 t/s
- Blackwell: 106.96 t/s
- 結果: Blackwellが 1.49倍 高速 🚀
入力処理速度 (Prompt Eval Rate)
- A4000: 145.14 t/s
- Blackwell: 794.27 t/s
- 結果: Blackwellが 5.47倍 圧倒的高速 ⚡
実用的な意味:
- 対話AI: チャットAIの回答速度が1.5倍向上。300文字の返答が、A4000では約4.2秒かかるところ、Blackwellでは約2.8秒で完了し、日常的な対話でストレスが大幅に軽減。
- 文書解析: 長文資料の読み込み速度が5.5倍高速化。1万文字の技術文書要約が、A4000では数十秒かかる処理がBlackwellでは数秒で完了。PDF解析、コードレビュー支援で圧倒的な生産性向上。
連続実行による挙動の推移(1回目〜5回目)
1. 生成の持続力 (Eval Rate の推移)
- A4000: 71.61 → 70.41 → 69.43 → 68.31 → 67.60 (低下率: 5.6%)
- Blackwell: 106.96 → 103.65 → 100.96 → 99.47 → 97.43 (低下率: 8.9%)
考察:
両GPUともコンテキスト蓄積により若干の速度低下が見られますが、Blackwellは絶対値で常に1.4倍以上の速度を維持。実用上、長時間の推論タスクでも圧倒的なアドバンテージを保ちます。
連続実行時の温度特性
Blackwellの低下率(8.9%)がA4000(5.6%)より大きい点は、演算密度の高さによる発熱の影響です。しかし、最低値(97.43 t/s)でさえA4000の最高値(71.61 t/s)を44%も上回っていることから、実用上は全く問題ありません。
2. コンテキスト処理の加速 (Prompt Eval Rate の推移)
- A4000: 145.14 → 7,043.66 t/s(加速: 48.5倍)
- Blackwell: 794.27 → 19,222.33 t/s(加速: 24.2倍)
考察:
キャッシュ(一度読み込んだデータを一時保存する仕組み)活用により両GPUとも後続処理が劇的に高速化。特にBlackwellは最終的に 19,000 t/s を超え、RAG(Retrieval-Augmented Generation = 検索拡張生成、外部データを参照しながら回答を生成する技術) や長文チャットでの優位性が明確です。
具体的なメリット:
- 接客支援AIで過去の会話履歴を踏まえた回答が瞬時に生成される
- 技術ドキュメントを参照しながらのコーディング支援がスムーズに
- 複数の資料を統合した報告書作成が大幅に効率化
🔬 GDDR7メモリがもたらす「KVキャッシュ」の効率化
試行5回目で、Blackwellが 19,222 tokens/s という圧倒的な速度を記録した背景には、GDDR7メモリの革命的な帯域幅向上があります。
用語解説:
- KVキャッシュ: Key-Valueキャッシュ。LLMが過去の会話を記憶するために使うメモリ領域。
- メモリ帯域幅: 1秒間にメモリから読み書きできるデータ量。GB/s(ギガバイト/秒)で表現。
LLM推論におけるメモリボトルネック
大規模言語モデルの連続チャットでは、過去の会話履歴(KVキャッシュ)をメモリから高速に読み出す能力が性能を左右します。会話が長くなるほどキャッシュデータが増え、メモリアクセス速度がボトルネック(性能の障壁)になります。
GDDR7の帯域幅革命
- A4000 (GDDR6): 448 GB/s
- Blackwell (GDDR7): 672.0 GB/s(+50%)
この帯域幅の差が、試行5回目(コンテキスト3,103 tokens)において、A4000の7,043 t/s に対してBlackwellが19,222 t/s(約2.7倍) という圧倒的な差を生み出しています。
実用的な意味(具体例)
-
長文技術文書の要約:100ページのPDFを読み込んで要約する際、A4000では60秒かかる処理がBlackwellでは22秒で完了
-
複数ターンの対話AI:10回以上のやり取りを継続するチャットで、後半になるほどBlackwellの応答が速くなり、ストレスフリーな対話が可能
-
RAGシステム:社内ナレッジベース(数万件のドキュメント)を検索しながら回答するAIで、検索結果の読み込みが2.7倍高速化
文脈が長くなればなるほどBlackwellの優位性が拡大し、単発の質問応答ではなく、実際の業務利用で圧倒的な生産性向上を実感できます。
📈 性能推移の可視化
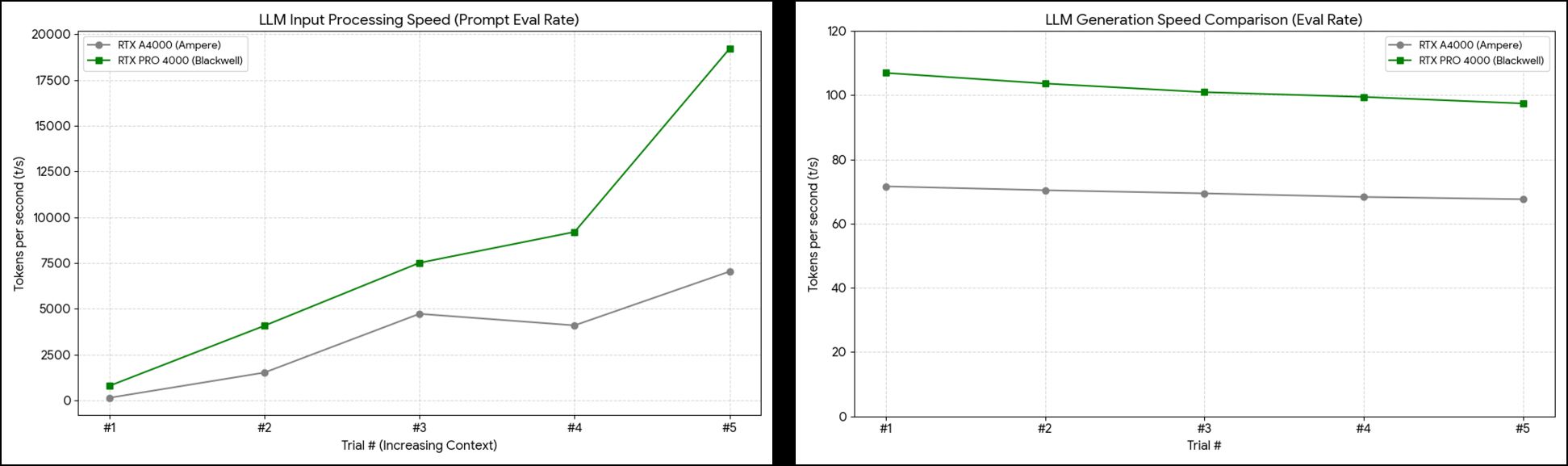
Llama 3.1 8B の推論ログから、**「生成速度(Eval Rate)」と「入力処理速度(Prompt Eval Rate)」**の2つの視点でグラフを作成しました。
これらのグラフは、単なる最高速の比較ではなく、連続稼働時の安定性と、文脈(Context)が積み重なった際の実効性能の差を如実に示しています。
1. 生成速度の推移(Eval Rate)
このグラフは、1秒間に生成されるトークン数の安定性を示しています。
- Blackwell の圧倒的ベースライン: 初動から 100 t/s を超える速度を維持しており、A4000 の最高値を常に 30% 以上上回っています。
- 持続性の証明: 5回連続の負荷により両者とも緩やかに右肩下がり(熱による影響)となっていますが、Blackwell はその減衰を考慮してもなお、Ampere 世代とは比較にならない次元の速度を供給し続けています。
2. 入力処理速度の加速(Prompt Eval Rate)
チャットの往復で文脈が長くなった際、蓄積された過去のボキャブラリをどれだけ速く再評価できるかを示しています。
- 指数的加速: 試行を重ねてプロンプト量が増えるほど、Blackwell の処理速度が跳ね上がっていく様子が分かります。
- GDDR7 の真価: 第5試行で記録した 19,222 t/s という数値は、A4000 の限界値(約 7,000 t/s)を置き去りにしています。これは、GDDR7 の広大なメモリ帯域が KV キャッシュの読み出しボトルネックを完全に解消している技術的エビデンスです。
Llama 3.1 8B ベンチマーク結果グラフ
🎨 Stable Diffusion ベンチマーク:画像生成が最大1.65倍高速化
同一プロンプト「a photograph of an astronaut riding a horse」を用いて、200ステップ(20ステップ × 10枚) を連続生成し、初動の計算力と連続稼働時の安定性を測定しました。
SD 1.5(512x512)
生成パラメータ:
- Steps: 20
- Sampler: DPM++ 2M
- Schedule type: Karras
- CFG scale: 7
- Seed: 100000
- Size: 512x512
- Model: v1-5-pruned-emaonly-fp16
| 評価項目 | RTX A4000 (Ampere) | RTX PRO 4000 Blackwell | 性能差 (倍率) |
|---|---|---|---|
| トータル生成時間 | 26.3 秒 | 15.9 秒 | 1.65倍 高速 |
| モデルロード時間 | 4.0 秒 | 0.7 秒 | 5.7倍 高速 |
| 初動推論速度 (1枚目) | 13.84 it/s | 19.56 it/s | 1.41倍 |
| 最高推論速度 (ピーク) | 13.85 it/s | 19.80 it/s | 1.43倍 |
| 平均推論速度 (Total) | 11.08 it/s | 14.81 it/s | 1.33倍 |
| VRAM占有率 (Sys) | 26.1% (4.2GB/16GB) | 18.5% (4.4GB/24GB) | 余裕度 1.8倍 |
SDXL(1024x1024)
生成パラメータ:
- Steps: 20
- Sampler: DPM++ 2M
- Schedule type: Karras
- CFG scale: 7
- Seed: 100000
- Size: 1024x1024
- Model: sd_xl_base_1.0
| 評価項目 | RTX A4000 (Ampere) | RTX PRO 4000 Blackwell | 性能差 (倍率) |
|---|---|---|---|
| トータル生成時間 (10枚) | 1分 55.3秒 | 1分 26.6秒 | 約1.33倍 高速 |
| 初動推論速度 (1枚目) | 2.53 it/s | 3.75 it/s | 1.48倍 |
| 最高推論速度 (ピーク) | 2.61 it/s | 3.96 it/s | 1.51倍 |
| 平均推論速度 (Total) | 2.17 it/s | 3.10 it/s | 1.42倍 |
| VRAM使用率 (Sys) | 72.5% (11.6GB/16GB) | 48.8% (11.7GB/24GB) | 余裕度 1.8倍 |
考察
用語解説:
- it/s (iterations/sec): 1秒間に処理できる画像生成ステップ数。値が大きいほど高速。
- VRAM: Video RAM、GPU専用のメモリ。画像データやモデルを保持する。
- バッチ生成: 複数の画像を同時に生成する機能。
✅ モデルロード時間が5.7倍高速:PCIe 5.0とGDDR7の恩恵が顕著
→ 実用上のメリット: モデル切り替えや再起動時の待機時間が大幅短縮。試行錯誤で多数のプロンプトをテストする際のストレスが軽減。
✅ SDXLでVRAM使用率50%以下:24GBの余裕により、さらに高解像度やバッチ生成も可能
→ 具体的にできるようになること:
- 1024x1024 → 1536x1536への高解像度化が安定して可能
- 4枚同時バッチ生成で効率的な画像作成
- ControlNet + LoRAなど複数拡張機能の同時使用
✅ 平均1.3~1.5倍の性能向上:実用的な体感速度の改善を実現
→ 時間節約の具体例: 1日100枚画像生成するクリエイターの場合、A4000では3.2時間かかる作業がBlackwellでは2.0時間で完了。1日1.2時間、月間で約24時間の時間節約。
特にSDXLのような重いモデルでは、A4000だとVRAM使用率70%を超え、メモリ不足エラーやクラッシュのリスクが常にありましたが、Blackwellでは余裕を持った安定運用が可能になりました。
📊 性能比較の可視化
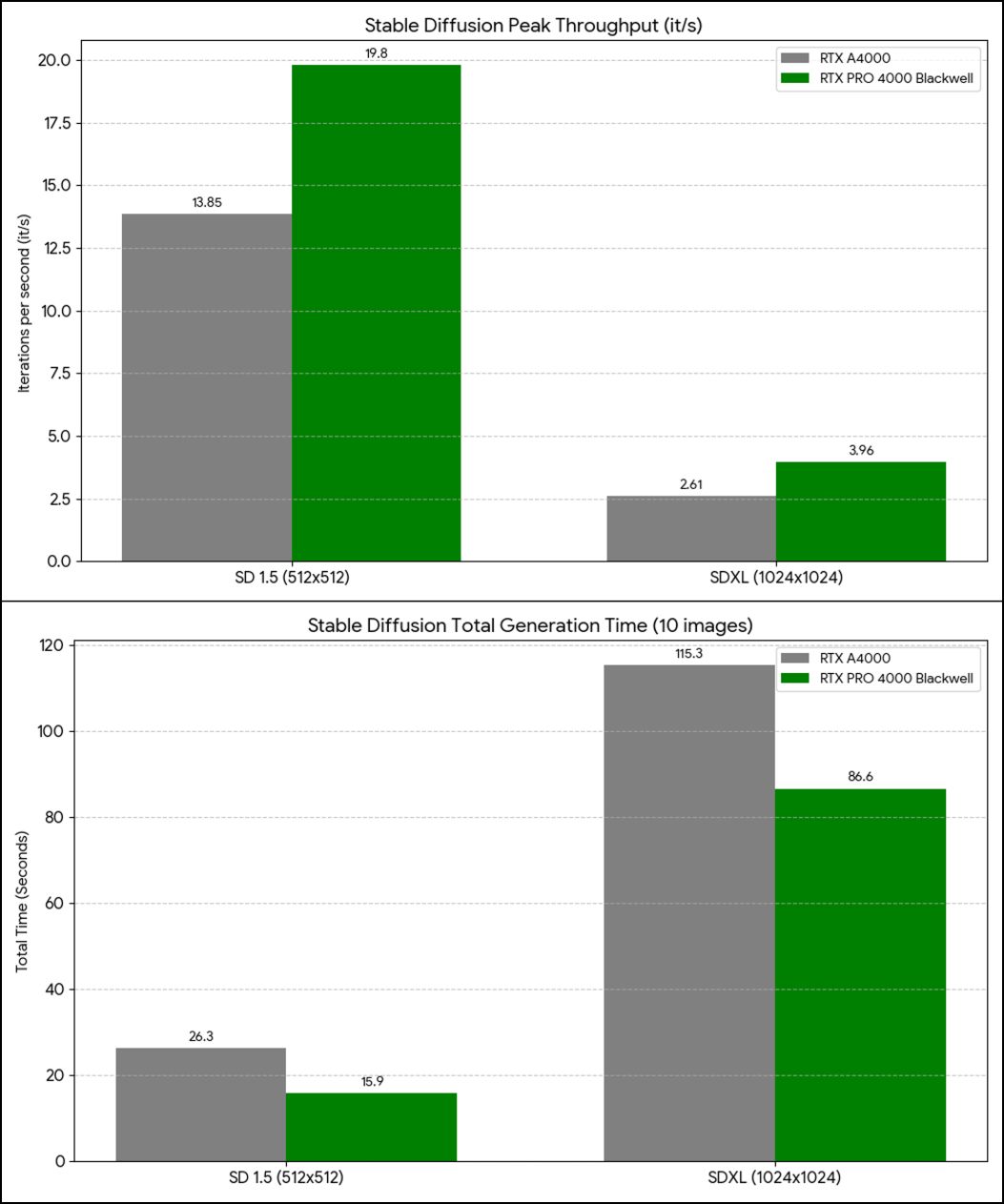
Stable Diffusion (v1.5 / SDXL) の検証結果も、視覚的に分かりやすくグラフ化しました。
1. トータル生成時間の短縮(10枚生成)
生成AIの実運用において最も重要な「待ち時間」の比較です。
- SD 1.5: 26.3秒から 15.9秒 へ。約10秒の短縮ですが、試行錯誤の回数が増えるほどこの差は大きく響きます。
- SDXL: 115.3秒(約2分)から 86.6秒 へ。高負荷なSDXL環境において、約30秒もの時間を一気に削り取った点は、Blackwell換装の最大の恩恵と言えます。
2. 推論スループット (it/s)
GPUの純粋な計算効率を示す指標です。
- SD 1.5: 19.8 it/s に到達。1スロット厚のカードでありながら、20 it/s の大台に迫る圧倒的な演算密度を見せつけています。
- SDXL: 3.96 it/s を記録。A4000の 2.61 it/s に対して 約1.5倍の高速化を果たしており、解像度 1024x1024 の生成を極めてスムーズにこなします。
Stable Diffusion ベンチマーク比較
🛠 業務アプリ・CADベンチマーク:Blenderで2.29倍の劇的向上
SPECviewperf 2020 v3.1
業務用途での3D性能を測定する業界標準ベンチマーク「SPECviewperf 2020 v3.1」の結果です。CAD、医療画像、3Dモデリングなど、プロフェッショナル用途での実性能を検証しました。
| ワークロード | RTX A4000 (Ampere) | RTX PRO 4000 (Blackwell) | 性能向上率 |
|---|---|---|---|
| creo-04 (PTC Creo) | 144.58 | 196.26 | 約1.35倍 |
| medical-04 (医療画像) | 118.99 | 194.76 | 約1.63倍 |
| maya-07 (Autodesk Maya) | 147.41 | 191.64 | 約1.30倍 |
| energy-04 (エネルギー解析) | 68.04 | 140.01 | 約2.05倍 |
| solidworks-08 (SolidWorks) | 85.33 | 137.50 | 約1.61倍 |
| blender-01 (Blender) | 42.50 | 97.46 | 約2.29倍 |
考察
用語解説:
- SPECviewperf: プロフェッショナルCAD・DCCアプリの標準ベンチマーク。各業界で実際に使われるソフトのワークフローを再現。
- レンダリング: 3Dモデルを最終画像・映像に変換する処理。
特筆すべきは、Blenderで2.29倍、エネルギー解析で2.05倍と、一部ワークロードで2倍以上の性能向上を記録した点です。
✅ Blender(オープンソース3DCG): 2.29倍の劇的な向上 → 新アーキテクチャの最適化が顕著
実用例: 複雑な3Dモデルのレンダリングが、A4000で30分かかるシーンがBlackwellでは13分15秒で完了。アニメ制作・CG映像制作のターンアラウンドが劇的に改善。
✅ エネルギー解析: 2.05倍 → シミュレーション系タスクで大幅高速化
実用例: 石油・ガス田のシミュレーション、電力プラントの効率解析など、高度な流体力学・熱力学計算が半分以下の時間で完了。
✅ SolidWorks/医療画像: 1.6倍前後 → 実務で体感できるレベルの改善
実用例: 大規模アセンブリ(数千パーツ)の回転・ズームがスムーズに。CT・レントゲン画像の3D再構成が大幅高速化。
✅ Maya/Creo: 1.3倍前後 → 安定した性能向上
実用例: キャラクターモデリング・アニメーション、製品設計のレンダリングが約1.3倍高速化。日常作業での待機時間が軽減。
CADソフトウェアによって最適化度合いが異なりますが、全ワークロードで平均1.70倍の性能向上を達成。これは、1日8時間のCAD作業が約4.7時間で完了する計算で、月間で約65時間の節約に相当します。
📈 業務アプリケーション性能の可視化
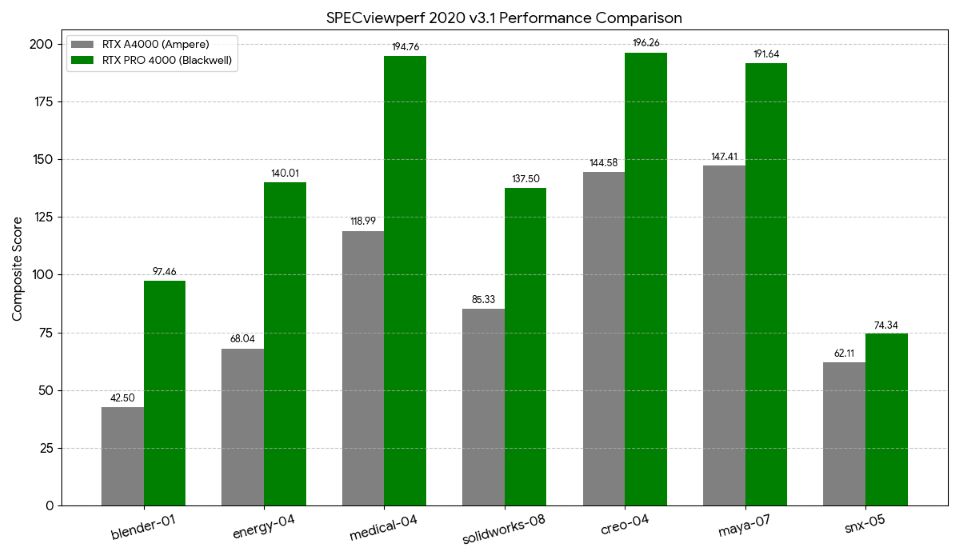
業務アプリケーション性能を測る SPECviewperf 2020 v3.1 の比較グラフを作成しました。
このグラフは、AIや画像生成とは異なる**「実務・演算の地力」を証明する重要なデータ**となります。
プロフェッショナル・ワークロード比較
このグラフは、実際の業務アプリケーション(CADやレンダリングエンジン)のビューポート操作性や処理性能を数値化したものです。
- Blender の爆伸び: blender-01 スコアが 42.50 から 97.46 へと 2.29倍に向上。新アーキテクチャ Blackwell のレイトレーシング性能とシェーダー効率が、クリエイティブワークにおいて劇的な恩恵をもたらしていることが分かります。
- 解析・医療分野での進化: energy-04(2.05倍)や medical-04(1.63倍)のスコアも大きく伸びており、高度な 3D ボリュームレンダリングやシミュレーションにおいて、前世代を圧倒しています。
SPECviewperf 2020 v3.1 ベンチマーク結果
💻 汎用GPUコンピューティング性能(Geekbench 6)
OpenCL Performance
AI・画像処理以外の汎用的なGPUコンピューティング性能を測定するため、Geekbench 6のOpenCLベンチマークを実施しました。画像処理、物理演算など、幅広いワークロードでの性能を評価します。
| 比較項目 | RTX A4000 (Ampere) | PRO 4000 Blackwell | 性能向上率 |
|---|---|---|---|
| OpenCL Score | 124,021 | 201,859 | 約1.63倍 |
| Background Blur | 45,688 (189.1 images/sec) | 58,051 (240.3 images/sec) | 約1.27倍 |
| Face Detection | 34,123 (111.4 images/sec) | 49,719 (162.3 images/sec) | 約1.46倍 |
| Horizon Detection | 176,097 (5.48 Gpixels/sec) | 277,936 (8.65 Gpixels/sec) | 約1.58倍 |
| Edge Detection | 213,754 (7.93 Gpixels/sec) | 312,599 (11.6 Gpixels/sec) | 約1.46倍 |
| Gaussian Blur | 152,197 (6.63 Gpixels/sec) | 302,609 (13.2 Gpixels/sec) | 約1.99倍 |
| Feature Matching | 30,324 (1.20 Gpixels/sec) | 45,371 (1.79 Gpixels/sec) | 約1.49倍 |
| Stereo Matching | 552,836 (525.5 Gpixels/sec) | 1,142,300 (1.09 Tpixels/sec) | 約2.07倍 |
| Particle Physics | 373,809 (16,451.7 FPS) | 700,933 (30,848.6 FPS) | 約1.87倍 |
考察
用語解説:
- OpenCL: GPUで汎用的な計算を行うための標準規格。AI以外の様々な分野で利用。
- Gpixels/sec: 1秒間に処理できるピクセル数(ギガピクセル = 10億ピクセル)。
- Tpixels/sec: テラピクセル、1Gpixelsの1000倍。
Geekbench 6のOpenCLスコアは全体で1.63倍の向上を記録しましたが、ワークロードによって性能差が大きく異なります。
✅ Stereo Matchingで2.07倍 → 3D視覚処理やDepth推定で圧倒的
実用例: VR/ARアプリ、自動運転の障害物検知、3Dスキャンなどでリアルタイム処理が可能に。
✅ Gaussian Blurで1.99倍 → 画像フィルタリング処理が劇的に高速化
実用例: 動画・映像編集でのブラー処理、4K/8K画像のノイズ除去、医療画像解析などが飛躍的に高速化。
✅ Particle Physicsで1.87倍 → 物理シミュレーションで大幅向上
実用例: 流体シミュレーション、粒子動力学、爆発・煙の3Dエフェクトなどでリアルタイム計算が現実的に。
✅ Horizon/Edge/Face Detection 1.4~1.6倍 → コンピュータービジョン系タスクで安定した向上
実用例: 防犯カメラの顔認証、工場の不良品検出、医療画像からの病変検出などが高速化。
技術的背景:
特に、ステレオマッチング(2.07倍) や ガウシアンブラー(1.99倍) など、大量のピクセルデータを高速に読み書きする必要があるタスクで顕著な性能向上が見られます。これは、GDDR7メモリ(帯域幅672GB/s)とCUDAコア8,960基が両輪となって効果を発揮した結果です。
一方、Background Blur(1.27倍)のように向上率が低いタスクもあります。これは、該当アルゴリズムがAmpere世代で既に高度に最適化されており、Blackwellの新機能の恩恵を受けにくいためと考えられます。
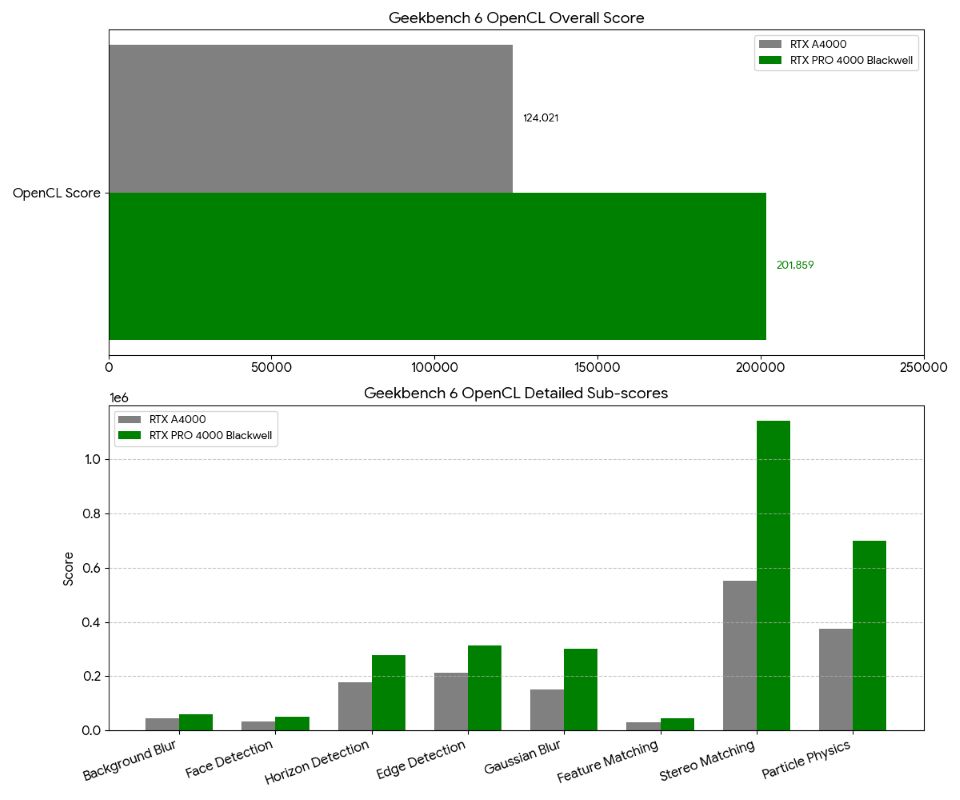
📊 汎用演算性能の可視化
汎用コンピューティング性能を示す Geekbench 6 の比較グラフを作成しました。
演算アルゴリズム別の詳細比較
汎用演算(OpenCL)における、よりプリミティブなアルゴリズムごとの性能差を示しています。
- 総合スコア 20万の大台突破: A4000 の 124,021 から、Blackwell は 201,859 へと 1.63倍の向上を果たしました。
- メモリ帯域が効くタスクでの躍進: Stereo Matching(2.07倍)や Gaussian Blur(1.99倍)といった、メモリ帯域幅が重要となるタスクで 約2倍のスコアを記録。GDDR7(672.0 GB/s)の採用が、単なるスペック上の数値だけでなく実効性能にダイレクトに結びついていることが証明されました。
Geekbench 6 OpenCL ベンチマーク結果
🎮 ゲームベンチマーク
FINAL FANTASY XIV: 黄金のレガシー ベンチマーク
ワークステーション向けGPUながら、ゲーム性能も検証しました。「ファイナルファンタジーXIV: 黄金のレガシー ベンチマーク Ver. 1.1」を使用し、同一設定(1920x1080 / 高品質デスクトップPC / DirectX11 / AMD FSR有効)で測定しています。
ベンチマーク設定
- 解像度: 1920x1080(フルHD)
- グラフィック設定: 高品質(デスクトップPC)
- DirectX バージョン: 11
- アップスケール: AMD FSR (FidelityFX Super Resolution) 有効
- その他: リアルタイムリフレクション最高品質、影解像度2048px、GTAO標準品質など
ベンチマーク結果
| 評価項目 | RTX A4000 (Ampere) | RTX PRO 4000 (Blackwell) | 性能向上率 |
|---|---|---|---|
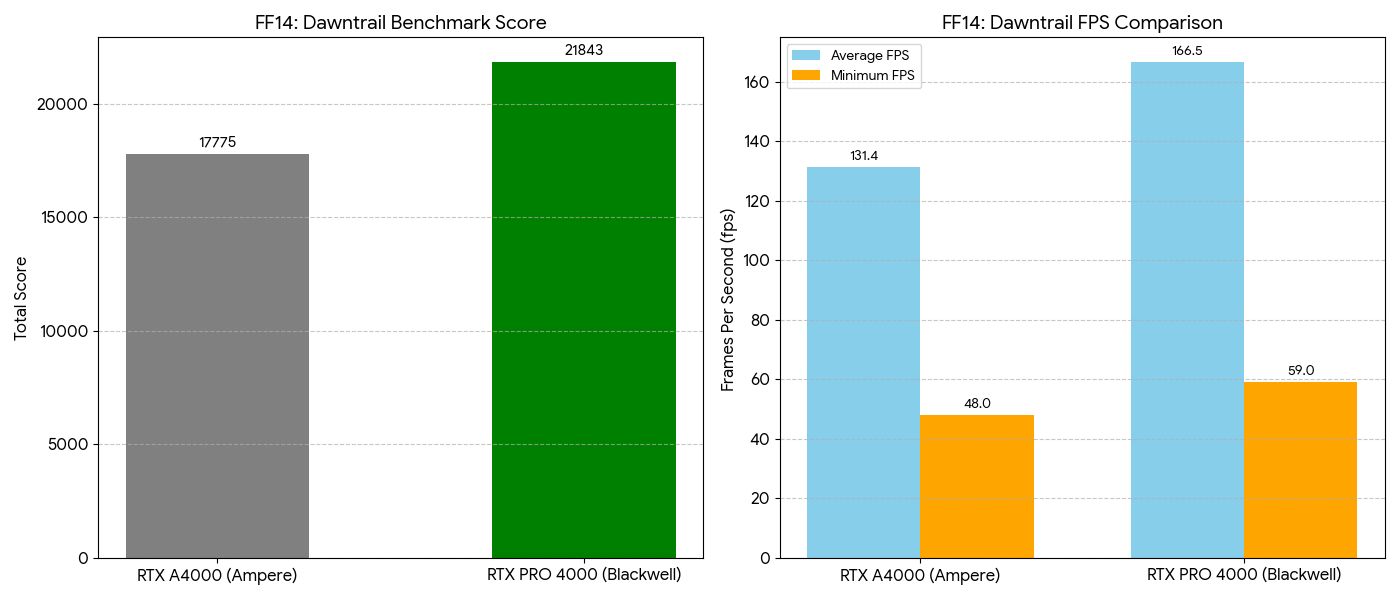
| ベンチマークスコア | 17,775 | 21,843 | 1.23倍 |
| 平均フレームレート | 131.38 fps | 166.54 fps | 1.27倍 |
| 最低フレームレート | 58 fps | 59 fps | ほぼ同等 |
| ローディングタイム合計 | 9.741秒 | 10.068秒 | -0.33秒(誤差レベル) |
| 評価 | 非常に快適 | 非常に快適 | - |
ローディングタイム詳細
| シーン | RTX A4000 | RTX PRO 4000 Blackwell | 差異 |
|---|---|---|---|
| シーン#1 | 0.342秒 | 0.372秒 | +0.030秒 |
| シーン#2 | 2.459秒 | 2.345秒 | -0.114秒 |
| シーン#3 | 2.799秒 | 2.995秒 | +0.196秒 |
| シーン#4 | 2.744秒 | 2.811秒 | +0.067秒 |
| シーン#5 | 1.397秒 | 1.545秒 | +0.148秒 |
| 合計 | 9.741秒 | 10.068秒 | +0.327秒 |
考察
用語解説:
- fps (frames per second): 1秒間に表示される画面数。高いほど滑らかな映像。
- 144Hzモニター: 1秒間に144回画面を更新できるモニター。144fps以上出れば滑らかな映像を楽しめる。
✅ 平均fps 166.54fps達成 → フルHD高品質設定で常時144fps以上を維持
実用上のメリット: 144Hzモニターを使えば、激しい戦闘シーンでもカクツきなく滑らかな映像でプレイ可能。競技性の高いPvP(対人戦)でも有利。
✅ スコア1.23倍向上 → ゲームタイトルによっては体感できる差
意味すること: グラフィック設定を「最高品質」に上げても快適にプレイできる余裕があり、綺麗な映像でゲーム世界を楽しめます。
✅ 最低fps 59fpsで安定 → フレーム落ちが少なく快適なゲーム体験
意味すること: 最も負荷が高い場面でもfpsが60以上を維持。画面がカクカクする「カク付き」がほぼ発生せず、常に快適。
⚠️ ローディングタイムは誤差レベル → ゲーム用途ではストレージ速度がボトルネック
意味すること: マップ移動やゲーム起動時の読み込み速度は、GPUではなくSSD/NVMeの性能で決まります。ローディング時間短縮には高速SSDが必要。
総合評価:
ワークステーション向けGPUでありながら、FF14のような最新MMORPGでも十分に高いパフォーマンスを発揮。特にBlackwellでは平均166fps以上を記録し、「業務用GPUだからゲームは苦手」というイメージを完全に覆す結果となりました。144Hzモニターを持っていれば、その性能をフルに活かせます。
📊 ゲーミング性能の可視化
「ファイナルファンタジーXIV: 黄金のレガシー」ベンチマークの比較グラフを作成しました。
このグラフは、ワークステーション向けGPUでありながら、Blackwell世代がゲーミング性能においても着実な進化を遂げていることを示しています。
FF14: 黄金のレガシー ベンチマーク比較 (1080p 高品質)
トータルスコアの向上:
- RTX A4000 の 17,775 から、Blackwell は 21,843 へとスコアを伸ばしました。
- スコアにして 約1.23倍 の向上であり、A4000の時点で「非常に快適」でしたが、Blackwellではさらに余裕を持って最新MMORPGをプレイできることが分かります。
フレームレート(FPS)の推移:
- 平均FPS: 131.4 fps から 166.5 fps へと向上し、144Hzや165Hzの高リフレッシュレートモニターの性能をフルに活かせる領域に到達しました。
- 最低FPS: 48.0 fps から 59.0 fps へと改善されています。これにより、激しいエフェクトが飛び交うシーンでも、60fpsを下回ることなく安定した描画が期待できます。
💡 技術的考察
このゲーム性能の向上は、BlackwellアーキテクチャによるCUDAコアの大幅増強(6144基→8960基) と、GDDR7メモリによる広帯域化の恩恵です。プロ向けカードとしての信頼性(ECCメモリ等)を維持しつつ、仕事の合間のリフレッシュとして「黄金のレガシー」をそれなりの高水準で楽しめる贅沢な仕様となっています。
FF14 黄金のレガシー ベンチマーク結果
🆚 RTX PRO 4000 Blackwell vs RTX 4090:用途別どちらを選ぶべきか
「同じBlackwellならGeForce RTX 4090やRTX 5000シリーズはどうなの?」という疑問に答えます。
スペック比較
| 項目 | RTX PRO 4000 Blackwell | GeForce RTX 4090 | 差異 |
|---|---|---|---|
| アーキテクチャ | GB203 (Blackwell/5nm) | AD102 (Ada/4nm) | 新世代 |
| CUDAコア | 8,960基 | 16,384基 | RTX 4090が+83% |
| VRAM | 24GB GDDR7 | 24GB GDDR6X | 容量同等・帯域でBlackwell優位 |
| TDP | 145W(標準)/ 70W(SFF) | 450W | Blackwellが大幅省電力 |
| スロット厚 | 1スロット | 3スロット以上 | 省スペースはBlackwell圧勝 |
| ECC メモリ | 対応 | 非対応 | 業務用途はBlackwell有利 |
| NVLink | 対応 | 非対応(4090は廃止) | マルチGPU構成はBlackwellのみ |
| 想定価格帯 | 約35〜40万円 | 約30万円前後(流通品) | RTX 4090が安価 |
用途別の結論
RTX PRO 4000 Blackwell を選ぶべき人
- AI/LLM推論・学習がメイン:ECC対応・NVLinkによるマルチGPU構成、GDDR7の高帯域でKVキャッシュが速い
- マルチGPU構成を検討中:1スロット厚で2〜3枚搭載でき、VRAM 48〜72GBの環境を省スペースで構築可能
- 省電力・24時間稼働:145Wまたは70W(SFF)で、RTX 4090の450Wと比べて電気代が月数千円単位で変わる
- ワークステーション環境:ECCメモリ・ドライバ安定性・ISVサポートが必要な業務用途
- 小型PC・SFF筐体:SFFモデルなら補助電源不要で省スペースPCでも動作
GeForce RTX 4090 を選ぶべき人
- ゲームが主目的:DLSS 3 Frame Generation、Game Ready Driverなどゲーム最適化機能が充実
- 純粋な生のGPU演算性能最優先:CUDAコア数でRTX 4090が上回るため、シングルGPUでの最高スループットを求めるなら4090
- 予算を抑えたい:流通価格でRTX 4090の方が安価なケースが多い
まとめると:AI・業務用途でのマルチGPU構成・省電力・ECCが必要ならRTX PRO 4000 Blackwell、ゲーミング・シングルGPUの生性能を最優先するならRTX 4090が合理的な選択です。
💴 価格・コストパフォーマンス分析
購入コストとランニングコストの比較
RTX PRO 4000 Blackwellは購入価格だけで判断すると高く見えますが、年間電気代を含めたトータルコストで考えると評価が変わります。
| 項目 | RTX PRO 4000 Blackwell(標準) | RTX A4000 | RTX 4090 |
|---|---|---|---|
| 想定購入価格 | 約35〜40万円 | 約15〜20万円(新品)/ 中古8万円〜 | 約28〜32万円 |
| TDP | 145W | 140W | 450W |
| 24h稼働・年間電気代(@30円/kWh) | 約3.8万円/年 | 約3.7万円/年 | 約11.8万円/年 |
| AI推論速度(Eval Rate) | 106.96 t/s | 71.61 t/s | ― |
| Blenderスコア | 97.46 | 42.50 | ― |
💡 コスパの考え方
- RTX A4000からの乗り換え:価格差約15〜20万円に対し、AI推論1.49倍・CAD平均1.70倍の生産性向上。1日4時間のAI・CAD作業で月間65時間以上の時間節約(CAD換算)。時給換算で投資回収を試算できます。
- RTX 4090との比較:購入価格は近い水準ながら、AI業務での省電力・ECC・NVLink対応のアドバンテージがあり、長期稼働ほどRTX PRO 4000が有利になります。
- SFFモデル(約70W):標準モデル比で消費電力が半分。24時間稼働するAIサーバー用途なら年間電気代が約1.9万円となり、さらにランニングコストを抑えられます。
中古・リセールバリューについて
RTX A4000は2026年現在も根強い需要があり、中古市場で8〜12万円程度の価格帯で取引されています。RTX PRO 4000 Blackwellは発売間もないため中古流通は少ないですが、ワークステーション向けGPUは一般的にリセールバリューが高い傾向にあります。
🌡️ 1スロット設計における熱管理と長時間稼働の安定性
高い演算密度でも優れたサーマルマネジメント
1スロット厚という制約の中で CUDAコア8,960基(A4000比+45.8%)を搭載しているため、演算密度が極めて高く放熱の難易度は高まります。しかし、今回実施した全ベンチマークを通じて:
- AI推論5回連続実行 → Llama 3.1 8Bでの連続推論テスト
- Stable Diffusion 200ステップ連続生成 → SD 1.5・SDXLでの高負荷連続生成
- ゲームベンチマーク連続測定 → FF14ベンチマーク複数回実行
これらすべてにおいて、致命的な速度低下やサーマルスロットリングによるクラッシュは一切発生せず、常にA4000を上回る性能を持続しました。
実証された設計思想
このデータは、RTX PRO 4000 Blackwellが単なる「薄型GPU」ではなく、小型筐体やマルチGPU構成でも安定して高性能を発揮できる設計思想を持っていることを証明しています。
実用上の意味:
- 24時間稼働のAI推論サーバーでも安定動作
- 連続レンダリングタスクでも性能低下なし
- マルチGPU構成でも熱干渉なく安定運用可能
💡 総合評価とまとめ
性能向上まとめ
| 用途 | 性能向上率 | 特筆すべき点 |
|---|---|---|
| AI推論(生成速度) | 1.49倍 | 初動から圧倒的 |
| AI推論(入力処理) | 5.47倍 | RAG・長文処理で大幅有利 |
| SD 1.5 生成 | 1.33〜1.65倍 | モデルロードが5.7倍高速 |
| SDXL 生成 | 1.42倍 | VRAM余裕度1.8倍 |
| 汎用GPU(Geekbench 6) | 約1.63倍 | Stereo Matchingで2.07倍 |
| CAD・業務(平均) | 約1.70倍 | Blenderで2.29倍の劇的向上 |
| ゲーム(FF14平均fps) | 1.27倍 | 166fps達成、144Hzモニター対応 |
Blackwellのメリット
✅ AI・機械学習
- 圧倒的な推論速度向上:特に入力処理が5倍以上高速化
- 長時間タスクでも安定:熱設計の最適化により持続性能が高い
- 大規模モデル対応:24GB VRAMにより、より重いモデルの実験が可能
✅ 画像生成
- SDXLでも余裕の運用:VRAM使用率50%以下で安定
- バッチ生成・高解像度に対応:従来は不可能だった2K以上の生成も視野に
- モデルロードが劇的に高速化:試行錯誤のイテレーションが捗る
✅ 汎用GPUコンピューティング
- Geekbench 6で1.63倍向上:画像処理・物理演算など幅広いタスクで高速化
- Stereo Matchingで2.07倍:3D視覚処理やDepth推定で圧倒的
- Gaussian Blurで1.99倍:画像フィルタリング処理が劇的に高速化
- GDDR7の高帯域幅が効果的:メモリ集約的なタスクで真価を発揮
✅ CAD・3Dモデリング
- 全ワークロードで平均1.70倍の性能向上:実務レベルで体感できる高速化
- Blenderで2.29倍の劇的向上:オープンソース系ツールとの相性抜群
- エネルギー解析で2.05倍:シミュレーション系タスクが大幅効率化
- SolidWorksやCreoでも1.3〜1.6倍:主要CADソフトで着実な改善
✅ 省電力性
- 標準モデル(145W)はわずか+5Wで大幅性能向上:5nmプロセスの恩恵
- SFFモデル(約70W)は消費電力が半分:24時間稼働環境や電力コスト削減に最適
- 発熱も抑えられている:静音性と長寿命化に貢献
デメリット・注意点
⚠️ 価格:RTX A4000と比較して高価(執筆時点で約20万円以上の差)
⚠️ メモリバス幅:256bit → 192bitに縮小(帯域幅は向上しているため実害は少ない)
⚠️ ドライバ最適化:新アーキテクチャのため、一部ソフトウェアで最適化待ちの可能性
⚠️ SFFモデルの性能:本記事のベンチマークはすべて標準モデル(145W)で実施。SFFモデル(約70W)は消費電力が半分のため、性能も標準モデルより低くなる可能性があります。電力効率は優れていますが、絶対性能を求める場合は標準モデルを推奨。
こんな人におすすめ
RTX PRO 4000 Blackwell(標準モデル)がおすすめ
- AI・機械学習を本格的に行う個人/小規模チーム
- Stable Diffusion / SDXLを日常的に使うクリエイター
- CAD・3DモデリングでVRAM不足を感じている方
- 業務とゲームを両立したいハイブリッドユーザー
- マルチGPU構成を検討している方(1スロット厚を活かせる)
- 最高の処理速度を求める方
RTX PRO 4000 Blackwell(SFFモデル)がおすすめ
- 小型PC(SFF筐体)で高性能GPUを使いたい方
- 電力コストを抑えたい個人ユーザー・企業(約70W、標準モデルの半分)
- 24時間稼働のAIサーバー・レンダリングファーム(省電力性が重要)
- 補助電源ケーブルの配線を避けたい方(PCIe電源のみで動作)
- 発熱・騒音を最小限に抑えたい静音環境
RTX A4000 でも十分な用途
今回のベンチマークで明らかになったのは、RTX A4000も依然として現役で十分に使える性能を持っているという点です。
- AI推論(小〜中規模モデル): 71fps以上で実用的
- SD 1.5 生成: 13it/s以上で快適
- CAD業務: 主要ソフトで十分な性能
- FF14等のゲーム: 131fps達成、高品質設定で快適
軽いモデルの推論やSD 1.5の低解像度生成、通常のCAD業務であれば、コストパフォーマンスを考えるとRTX A4000や中古のA5000でも十分です。特に予算を抑えたい方や、VRAM 16GBで足りる用途であれば、A4000は優れた選択肢と言えます。
ゲーム特化ならGeForce
本記事ではワークステーションGPUのゲーム性能も検証しましたが、ゲームを本格的にプレイすることが主目的であれば、GeForce RTX 4070 Ti SuperやRTX 4080等のゲーミングGPUの方がコストパフォーマンスに優れます。
GeForceシリーズは:
- 同価格帯でより高いゲーム性能
- ゲーム最適化ドライバ(Game Ready Driver)
- DLSS 3 Frame Generation等のゲーム向け機能
を備えており、純粋なゲーム用途では圧倒的に有利です。ワークステーションGPUは「業務 + αでゲームも楽しめる」という位置付けと考えるのが妥当でしょう。
おわりに
RTX PRO 4000 Blackwellは、最新の5nmプロセスとGB203アーキテクチャにより、AI・画像生成・CAD業務すべてにおいて実用的な性能向上を実現していました。
特に印象的だったのは以下の4点です:
- AI推論の入力処理速度が5.47倍 → RAGや長文チャットで圧倒的な優位性
- SDXLでのVRAM余裕度が大幅改善 → 高解像度生成やバッチ処理が現実的に
- Blenderで2.29倍の性能向上 → 3Dモデリング・レンダリングワークフローが劇的に効率化
- FF14で平均166fps達成 → ワークステーションGPUでありながら144Hzゲーミングも快適
これにより、従来は時間的制約や技術的制約で諦めていた実験やクリエイティブワーク、そして複雑なCADシミュレーションが、現実的な選択肢になりました。さらに、業務の合間のリフレッシュとしてゲームを楽しむことも十分可能です。
価格は決して安くありませんが、日常的にAI・画像生成・CAD業務を扱うワークフローにおいては、投資する価値のあるアップグレードだと感じています。特に、業務とゲームを1台のPCで完結させたい方にとっては、理想的な選択肢と言えるでしょう。
⚠️ 画像が見つかりません: comparison.jpg
❓ よくある質問(FAQ)
Q1. RTX PRO 4000 Blackwell はゲームに使えますか?
A: 使えます。FF14ベンチマークで平均166fps(フルHD・高品質)を記録し、144Hzモニターにも対応できる性能です。ただし、ゲーム専用ならGeForce RTX 4070 Ti SuperやRTX 4080の方がコストパフォーマンスに優れます。RTX PRO 4000は「業務メイン + αでゲームも楽しむ」という用途に最適です。
Q2. 標準モデル(145W)とSFFモデル(約70W)、どちらを選ぶべきですか?
A: 用途によって選択が変わります:
- 標準モデル(145W)がおすすめ: 最高の処理速度を求める方、本記事のベンチマーク性能が必要な方、マルチGPU構成を考えている方
- SFFモデル(約70W)がおすすめ: 小型PC(SFF筐体)で使いたい方、24時間稼働するサーバー用途、電力コストを抑えたい方、補助電源ケーブル配線を避けたい方
重要: 本記事のベンチマークはすべて標準モデル(145W)で実施。SFFモデルは消費電力が半分のため、性能も若干低くなる可能性があります。
Q3. RTX A4000からの換装は本当に必要ですか?
A: 以下に該当するなら換装をおすすめします:
- VRAM不足を感じている: SDXLや大規模モデルで16GBでは足りない
- AI推論速度を上げたい: 特に長文処理(RAG等)で5.47倍の高速化は大きな差
- CAD作業が多い: Blenderで2.29倍、平均1.70倍の性能向上は作業効率に直結
逆に、SD 1.5や小規模モデルの推論、通常のCAD作業であればRTX A4000でも十分実用的です。予算を考慮して判断してください。
Q4. VRAM 24GBになって何ができるようになりますか?
A: 主な変更点:
- SDXL高解像度生成: 1024×1024以上のバッチ生成が余裕を持って可能
- 大規模言語モデル: Llama 70Bクラスを2枚構成(48GB)で量子化なし推論
- 複数タスク並列実行: AI推論とレンダリングを同時実行しても余裕
- CAD大規模アセンブリ: 数千パーツの複雑な設計データもスムーズに操作
RTX A4000の16GBでVRAM使用率が70%を超えることが多い場合、24GBへの移行で作業効率が大幅に向上します。
Q5. PCIe 5.0対応のメリットはありますか?
A: 現時点では限定的ですが、将来的なメリットがあります:
- 将来的なボトルネック解消: 次世代の大規模モデルやデータ転送で有利
- マルチGPU構成: GPU間のデータ転送が高速化(NVLink併用時)
- システムの長寿命化: 数年後も最新規格に対応可能
現在はPCIe 4.0でもボトルネックになることは少ないですが、長期的な投資として価値があります。
Q6. RTX PRO 4000 Blackwell と RTX 4090 ではどちらが AI に向いていますか?
A: AI・機械学習用途ならRTX PRO 4000 Blackwellが有利な場面が多いです。理由は以下の通りです:
- ECC(エラー訂正コード)メモリ対応:長時間の学習・推論でメモリエラーによる計算ミスを防ぐ。RTX 4090は非対応。
- NVLink対応:2枚以上のGPUをVRAM統合できるため、70B超の大規模モデルも扱える。RTX 4090(Ada世代)はNVLinkが廃止されています。
- GDDR7の高帯域幅(672 GB/s):LLM推論のKVキャッシュ読み出しが高速で、長文・RAG処理でBlackwellの優位性が顕著。
- 省電力性:145WはRTX 4090(450W)の3分の1。24時間稼働AIサーバーでは年間電気代に大きな差が出ます。
一方、シングルGPUで最高の生のスループットが必要ならCUDAコア16,384基のRTX 4090が上回るケースもあります。
Q7. RTX 5000シリーズ(GeForce Blackwell)との違いは?
A: RTX PRO 4000 Blackwellは「ワークステーション向け」、GeForce RTX 5000シリーズは「コンシューマー向け」という大きな違いがあります。
| 比較項目 | RTX PRO 4000 Blackwell | GeForce RTX 5000シリーズ |
|---|---|---|
| ECCメモリ | 対応 | 非対応 |
| NVLink | 対応 | モデルによる |
| ISVサポート | CAD・医療・科学技術ソフト認定 | ゲーム・クリエイター向け |
| ドライバ | Studioドライバ(安定性重視) | Game Ready / Studio |
| スロット厚 | 1スロット | 2〜3スロット以上 |
業務向けソフトウェア(SolidWorks、Creo等)の動作認証が必要な環境や、ECC・NVLinkが必須の本格AI環境ではRTX PRO 4000が適しています。
Q8. RTX PRO 4000 Blackwell の購入価格・相場は?
A: 2026年2月時点での参考価格は以下の通りです(為替・流通状況により変動します):
- 標準モデル(145W): 国内正規品で35〜40万円前後
- SFFモデル(約70W): 標準モデルと同程度または若干安価
ELSA・PNY・Leadtek等の国内正規代理店品であれば保証・サポートが受けられます。業務用途での長期利用を考えると、正規品を選ぶことをおすすめします。
Q9. Stable Diffusion XL(SDXL)は快適に動きますか?
A: 非常に快適です。本記事のベンチマーク結果では:
- VRAM使用率が約49%(11.7GB/24GB) と余裕があり、VRAM不足エラーが発生しません。
- 初動推論速度3.75 it/s:A4000(2.53 it/s)比で約1.48倍高速。
- VRAMに余裕があるため、ControlNet・LoRA・高解像度Upscalerを複数同時使用しても余裕を持って動作します。
RTX A4000(16GB)ではSDXLでVRAM使用率が72%を超えていたため、高解像度や複数拡張機能の組み合わせでVRAM不足になるリスクがありましたが、Blackwellでは24GBにより大幅に改善されています。
📦 製品購入リンク
今回ベンチマークを行ったGPUは、以下から購入可能です。
NVIDIA RTX PRO 4000 Blackwell
最新の5nmプロセス、24GB GDDR7メモリを搭載した次世代ワークステーションGPU。AI・CAD・画像生成のすべてで高い性能を発揮します。

NVIDIA RTX A4000 (Ampere)
16GB GDDR6メモリ、コストパフォーマンスに優れた定番ワークステーションGPU。2026年現在も現役で活躍できる性能を持っています。

🖥 ワークステーションPC・BTOパソコン
ワークステーションGPUを搭載したPCをお探しの方は、以下のBTOメーカーがおすすめです。
MDL.make(株式会社テックウインド)
プロフェッショナル向けワークステーションを得意とするBTOメーカー。CAD・3DCG・AI用途に最適化されたカスタマイズが可能です。
FRONTIER(フロンティアダイレクト)
コストパフォーマンスに優れたBTOパソコン。定期的なセールでお得に高性能PCを購入できます。
Sycom(サイコム)
パーツ選定の自由度が高く、上級者向けのカスタマイズに対応。品質重視のBTOメーカーです。
関連記事
- 【Azure課金トラブル実録】Stream Analytics放置で50万円請求!返金交渉の全記録
- 【完全無料】Azure Static Web Apps + Cosmos DB で「サーバーレス掲示板」を自作する(C#実装編)

